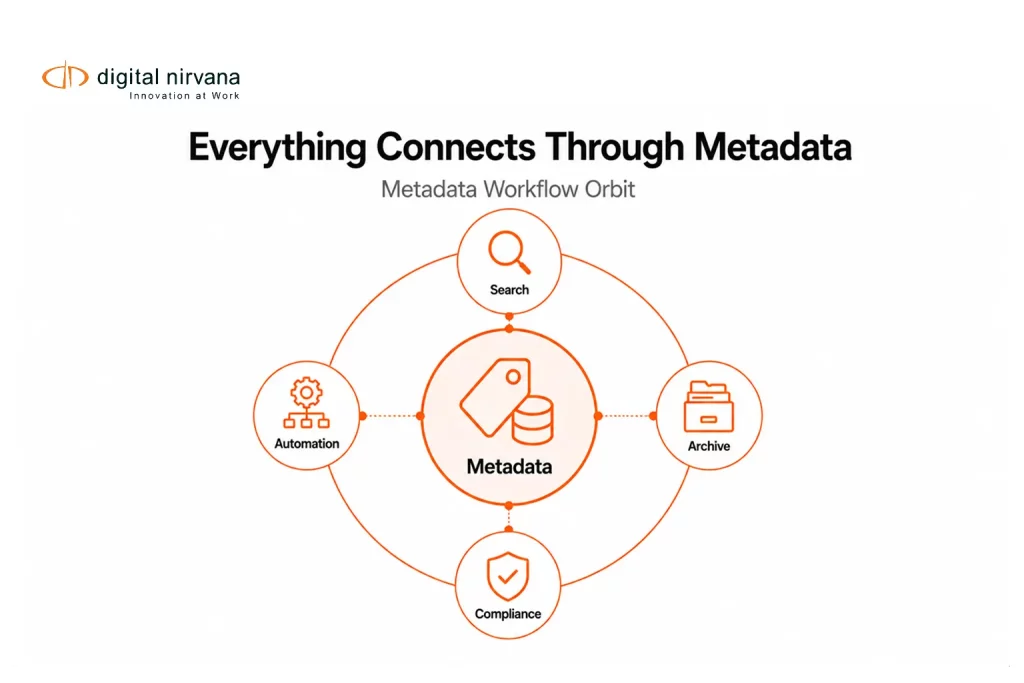
Production metadata drives how fast you find shots, how clean you clear rights, and how well you monetize a back catalog. Teams that treat File Metadata, Content Metadata, and Video Metadata as first-class assets finish faster and reuse more. AI now reads speech, recognizes faces and logos, and extracts text to build accurate, timecoded tags your editors trust. Clean Metadata cuts re-shoots, streamlines ESI Discovery handoffs, and supports captioning, disclosure, and distribution. When you align Metadata Types to real work, your Website, apps, and servers deliver the right cut to the right audience at the right time.

Why production metadata accuracy matters for media ROI
Accurate production metadata lifts revenue, reduces risk, and saves hours across film, series, news, and sports. Strong tags turn search into seconds, not hunts. Rights and consent sit next to the cut, so legal teams make quick calls with high admissibility. Clear IDs and Distribution Metadata enable platform packaging without guesswork. Finance leaders care because less waste and fewer delays deliver measurable ROI.
Find fast, reuse more, and monetize the back catalog
Well-formed Metadata and Catalog Data convert hard drives into searchable stores that pay rent. Editors filter by Keywords, people, location, and action with high relevance. Visual and speech cues become data, which powers exploration across seasons and franchises. With Business Metadata that tracks campaigns and targets, marketers lift views and conversions. Your library stops aging and starts working.
Meet captioning, accessibility, and legal requirements
Accurate File Metadata supports captions, audio description, and compliance records that regulators and platforms require. Speech to text with speakers reduces caption cleanup and feeds PDF Export for proceedings. Legal teams map Bates Number ranges to clips and documents, tie Email and Email Production to scenes, and export PDF Files, JPEG Files, and Spreadsheets with DocumentInfo fields for disclosure. Clean Creation Metadata, Definition Metadata, and Distribution Metadata help reviewers prove provenance and chain of custody in court. For platform rules on accessibility, review the FCC’s closed captioning guidance for TV to align QC checks with regulation (FCC TV captioning).
Cut re-shoots and speed up turnarounds across shows
When crews capture scene, shot, take, and lens data the same way every day, editors stitch timelines without gaps. Producers request fewer pickups because they can verify coverage inside the metadata. AI-backed logging flags continuity risks early, which protects schedules. Marketing pulls names, credits, and sponsor rules from the same record and ships social versions without delay. Time saved in post lands as faster delivery and fewer late nights.
How Digital Nirvana helps right now
Our services at Digital Nirvana focus on practical gains you can measure this quarter. MetadataIQ automates timecoded tagging across speech, faces, logos, OCR, and shot boundaries so editors find moments fast. MonitorIQ records, searches, and verifies playout with compliance logging for captions, loudness, and ads. TranceIQ accelerates transcription, captioning, and subtitle QC with review controls that fit broadcast timelines. Our closed captioning services handle complex turnarounds at scale while preserving lineage and DocumentInfo in sidecars. Each solution preserves File Metadata and rights notes so editors, engineers, and legal teams move in step.
Production workflow metadata across capture, edit, and delivery
Production workflow metadata moves from set to archive with context intact. You record the means of capture on set, align assets during ingest, enrich them in edit, and lock them in finishing. Delivery wraps fields into platform specs and Production Format packages that downstream tools read. Archive policies preserve value through clear retention rules and retrieval patterns. Treat each stage like a handoff where structure, timing, and identity stay tight.
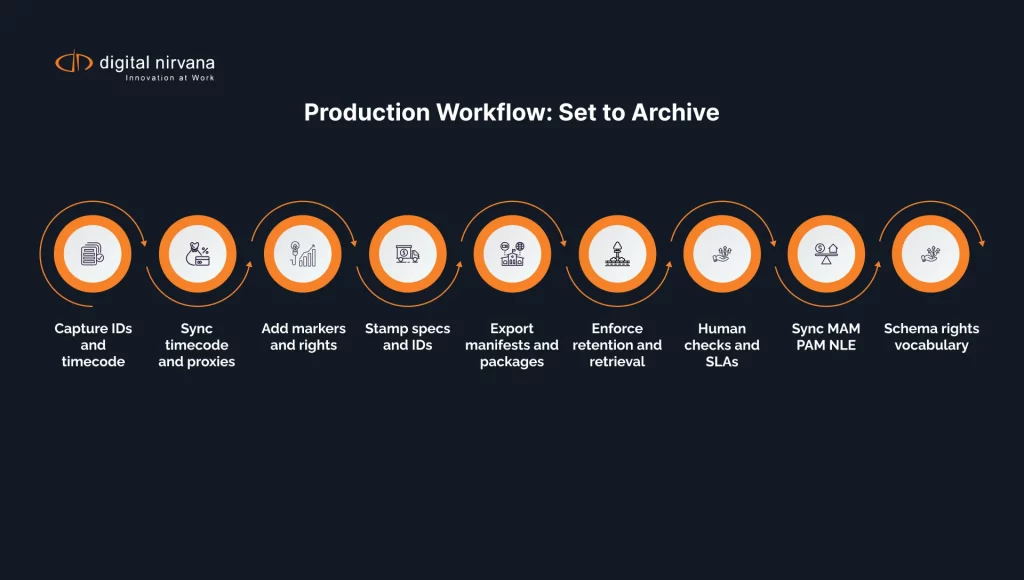
On set: camera, audio, slate, and script notes
On set, crews create the first layer of Metadata Elements. Cameras stamp timecode, reel IDs, lens data, and ISO. Audio devices store sample rate, channel maps, and File System Data such as creation and modify times. Slates and script notes add scene, shot, take, character, and continuity. The script supervisor’s notes anchor later AI enrichment because those notes define who says what and when. Good Metadata Practices here save days later.
Ingest: timecode sync, proxies, and sidecar files
During ingest, teams sync timecode across cameras and audio so every event lines up. Proxies preserve timecode, color space, and reel IDs while reducing size. Sidecar JSON or XML holds Storage Metadata, System Metadata, and a System Metadata File with authoritative fields. Disk Metadata Collection captures inode, ctime, and extended attributes for traceability. Normalized file names and a template-based folder plan keep data sources clear across servers and storage tiers.
Edit: markers, shot lists, and version control
Editors enrich Content Metadata with markers, ranges, and comments that call out beats and b-roll. Assistants maintain shot lists and stringouts with sane naming so context stays obvious. Version control tracks rough and fine cuts, mixes, and approvals, which preserves lineage. Producers add rights notes, usage windows, and consent next to Data Items so legal checks take minutes. The NLE’s user interfaces surface AI input without forcing extra clicks.
Finishing: color, titles, captions, and deliverables
Finishing converts editorial intent into frames, audio, and documents that platforms accept. Color and mix teams stamp LUTs, loudness values, and deliverable IDs so QC can certify compliance. Title cards, credits, captions, and audio description attach with aligned timecodes. Delivery tools export platform manifests and web application packages, including languages and access services. Preservation wins because masters carry clear IDs, EIDR, and Distribution Metadata through the final handoff.
Archive: retention rules and retrieval patterns
Archive strategy keeps assets available, legal, and cost controlled. You define retention policies by show, region, and rights, then enforce deletion on schedule. Search patterns shape index design because editors and marketers query by person, topic, location, and moment. Cold, warm, and hot tiers share IDs and lineage so movement across Data Storage stays transparent. With clean lineage, you can resurrect a season years later and still ship deliverables in spec.
How AI lifts production metadata accuracy end to end
AI adds speed and precision at each stage when you design for it. Models listen to speech, recognize faces and logos, read on-screen text, and detect shot boundaries at scale. You tune for precision on risky tasks and recall for discovery tasks, based on business goals. Human review closes the loop and teaches models where it matters most. With the right feedback, accuracy climbs and cost per hour drops.
Speech-to-text, topic extraction, and entity tagging
Modern ASR turns dialogue into timecoded text that feeds captions, search, and translation. Topic extraction groups segments by themes to build story arcs quickly. Entity tagging identifies people, places, and organizations so editors filter by who appears and where. You tune vocabularies with show terms, alternate spellings, and language codes to lift accuracy. Those signals power Metadata Discovery across the library. For practical tips, see our post on AI metadata tagging.
Face, object, logo, and scene recognition at scale
Vision models detect faces, props, uniforms, and brand marks across hours of footage with consistent rules. You attach detections to time ranges so editors find product shots fast or avoid unlicensed logos. Scene recognition classifies settings like office or stadium, which speeds b-roll searches. Watchlists for talent or partners simplify sponsorship tracking and compliance. Scale matters, and AI provides coverage manual logging cannot match.
OCR for slates, lower thirds, and signage in frame
OCR reads slates, lower thirds, and signs to capture names and locations as printed. That data prevents typographic errors in captions and credits. When OCR aligns with timecode and shots, editors jump to the first mention of a name. You validate names against a controlled vocabulary to remove drift. Clean OCR reduces metadata issues that cause late fixes.
Shot boundary detection and visual similarity search
Shot boundary detection segments a timeline into shots so editors see structure without scrubbing. Visual similarity search finds related shots by framing and motion, which speeds montages and trailers. Systems store links as Content Metadata so future teams benefit from prior work. That compounding value keeps the catalog fresh without new shoots. Results improve as models learn your dataset and style. To compare tools that pair well with deep tagging, explore our guide to digital asset management platforms.
Language ID and translation fields for multilingual cuts
Language identification flags spoken languages at the segment level for platform deliverables. Translation fields capture source text, target text, and reviewer approval for each language. Editors switch tracks with confidence because they see what changed and who approved it. Global releases ship faster because language metadata stays aligned. Multilingual planning belongs in the schema from day one.
Design a metadata schema that AI can learn and scale
A good schema gives people and machines the same map. Start with goals, then define entities, attributes, relationships, and Datatype choices in plain terms. Choose standards and IDs so systems talk without custom glue. Place rights and consent next to creative fields so checks happen early and often. With structure and governance, AI models learn consistent patterns.

Map taxonomies and controlled vocabularies to real use
Taxonomies only help if they match how teams search and work. Interview editors to learn their words for actions, genres, and moods, then encode those terms. Keep controlled vocabularies for names, places, and recurring segments so tags stay stable. Provide synonyms and aliases that map to preferred labels to catch spelling drift. Review usage each quarter and adjust the list so language reflects real production.
Choose open standards, IDs, and interoperable fields
Pick IDs and field names other tools recognize so you avoid lock in. Use EIDR, ISAN, and IETF language codes where they apply, and document how you populate each one. Maintain a crosswalk that maps internal labels to JSON and XML for exchange across servers. Favor sidecar files when native formats fall short so you protect camera originals. Interoperability turns your stack into one system instead of silos. For government-grade guidance on required elements, see NARA’s metadata requirements for permanent electronic records (NARA guidance).
Capture rights, usage windows, and consent details
Place rights at the center of the schema. For each asset, track contracts, usage windows, geographies, and restrictions in clear fields. Link release forms and consent notes to exact scenes so reviewers do not guess. Include union, music, and sponsor flags that affect cutdowns and platform variants. With rights data first, you avoid late surprises.
Plan multilingual tags, synonyms, and spelling variants
Global catalogs demand language aware metadata. Add fields for language, region, and script, and keep canonical labels with localized variants that roll up. Provide synonym rules for common phrases and slang so search still works when terms differ. Store transliterations for names that cross scripts, and teach AI valid spellings. This plan raises recall while keeping reports clear.
Common Metadata and EIDR IDs in plain terms
Think of EIDR as a durable ID that identifies a title or version like a VIN does for a car. Pair that ID with episode, season, clip, and asset IDs so every file knows its family. Keep simple field names such as title, synopsis, series_id, eidr, release_status, language_code, and creation metadata timestamps. Use business metadata to record campaigns and markets. When you adopt these basics, tools align and your metadata stops drifting.
Build a production metadata pipeline that keeps context
A resilient pipeline preserves time, identity, and lineage from capture to deliverable. You enforce timecode alignment, keep sidecars intact, and orchestrate updates through event APIs rather than manual exports. Systems broadcast changes so the MAM, PAM, and NLE stay in sync. Every step records provenance so you can audit what changed and why. This discipline protects context, which protects accuracy.
Keep timecode alignment across cameras and audio
Timecode acts like the spine of a project. Jam sync cameras and audio on set, verify during ingest, and run checks before edit begins. If you see drift, correct it once with a documented process rather than ad hoc fixes. Teach editors to preserve original timecode when they create proxies. With alignment locked, AI and humans share the same timing language.
Use sidecar JSON and edit decision lists for traceability
Sidecars store truth about media without touching originals. Keep JSON or XML that carries technical and creative fields, and version it when values change. Export edit decision lists that describe which source ranges feed each cut so reviewers can trace any frame. Store artifacts next to media and replicate them with the same rules as footage. This plan builds trust and shortens audits.
Sync MAM, PAM, and NLE with event-driven APIs
Event-driven APIs let systems publish and subscribe to changes. When editors add a marker or producers approve a caption, the MAM hears it and updates records. When AI adds a detection, the NLE shows it inside the timeline. That flow reduces duplicate work and lowers error rates because systems share one source. Data communication stops being a mystery and becomes part of your functionality.
Preserve lineage from raw ingest to mastered deliverable
Lineage shows where a frame came from and what changed along the path. Assign stable IDs at ingest, carry them through proxies and exports, and store mappings in the MAM. Record approvals, QC passes, and legal checks with timestamps and users so audits take minutes. When you ship a master, embed a manifest with components and rights status. Preservation starts with clear lineage.
Raise accuracy with human-in-the-loop review
Human in the loop turns AI into a teammate. You set thresholds that trigger auto approval for easy cases and review for risky ones. Reviewers teach models by correcting tags and confirming good calls. Subject experts handle edge cases that require domain knowledge or legal judgment. With clear roles and metrics, quality rises without slowing the schedule.
Set confidence thresholds and auto-approve rules
Define thresholds by task so teams do not debate each case. Approve faces above a high score for b-roll discovery, but route logo detections to review because risk runs higher. Auto accept short, high confidence ASR segments to speed captions while you flag tricky names. Tune thresholds as models improve and keep queues small. Publish rules so editors understand each call.
Train reviewers to teach models with active learning
Reviewers do more than fix mistakes. Use active learning to present borderline cases where feedback carries the most value. Provide short playbooks with examples, pitfalls, and preferred labels so reviewers work the same way. Track corrections by type and show the lift you gain to reinforce good habits. When reviewers see impact, they engage more and models improve faster.
Route edge cases to subject experts for final calls
Some decisions require legal, brand, or editorial judgment. Build queues that route those cases to named experts who own the call. Give them context such as contract terms, style guides, and prior rulings so they work fast. Log the decision and rationale so future reviewers follow the precedent. This structure keeps risk low without bottlenecks.
Define turnaround SLAs and escalation paths
Publish clear turnaround targets for reviews and match staffing to each show. Track queue time and a simple metric we call successful waiting, which counts tasks that met SLA without escalation. Define steps when queues grow, including extra reviewers or threshold tuning. Communicate daily status so producers plan with real capacity. Measure throughput and first pass yield to catch process issues early.
Guard against AI drift, bias, and privacy risks
AI changes as data and usage change, so you manage it like a critical system. Benchmark models on real show data before rollout and refresh on a schedule. Rotate training sets to reflect seasons, new talent, and evolving topics. Mask personal data you do not need, enforce retention, and audit access like a bank would. Controls let you enjoy AI speed without avoidable risk.
Benchmark models on real show data and refresh cycles
Test models against footage that matches your genre, lighting, accents, and camera styles. Record precision and recall for each task and define minimum scores you accept. Schedule refreshes so the benchmark stays current as shows and crews change. Share results with leads so everyone understands strengths and limits. Treat benchmarking as routine to avoid surprises.
Rotate training sets and watch for seasonal content shifts
Content shifts across the calendar, and models must follow. Rotate examples as new characters, uniforms, and locations appear. Track errors by show and season to see when a model falls behind and needs new data. Keep a notebook of edge cases and add them to training so the next cycle improves. This rhythm keeps accuracy high all year.
Mask PII, follow retention policies, and audit access
Protect people first. Mask or drop personal data that does not serve production. Set retention by business need and law, then delete on schedule with proof. Limit access by role and log who saw what and when so audits go fast. Design privacy into the workflow to earn partner trust.
Production workflow metadata for live news and sports
Live news and sports demand real time metadata that does not miss a beat. Transcripts, highlights, and clip IDs must land as the action unfolds. Rundowns must sync with markers in the switcher and NLE. Geo and rights rules must apply instantly so blackout and sponsorship policies hold. With the right setup, you clip, clear, and publish while the game or briefing continues. For practical dashboards that connect compliance with search and brand health, see how broadcasters apply media listening tools.
Real-time transcripts, highlights, and clip IDs
Real time ASR feeds lower thirds, captions, and search while producers mark key plays and quotes. Automated highlight detection flags peaks in crowd noise, motion, and commentary intensity for editors to confirm. Systems assign clip IDs at creation so downstream tools track usage and rights from second one. Editors publish to digital and linear targets from the same timeline. Your library gains tagged assets for future packages.
Rundown sync, segment markers, and ad break ties
Your rundown defines the show, so markers in the NLE must mirror it. Event updates push changes from the newsroom system to timelines and switchers. Segment markers align with ad breaks and sponsor billboards so compliance checks run clean. When the control room moves a block, the metadata moves with it. This sync turns chaos into a managed flow during breaking events.
Geo rules, rights windows, and blackout controls
Live events include distribution rules you must enforce in real time. Store geo fences, start and end windows, and platform clauses as fields your playout system can read. Apply those rules to clips and streams at the edge so regions see only what contracts allow. Log each block and allow decision for proof, and alert teams when rules conflict. Strong rule metadata protects deals and reduces takedowns.
Measure value: KPIs that prove metadata pays
Leaders fund what they can measure, so you tie metadata to money. Track search time saved, reuse rates, caption throughput, QC pass rates, and takedown reductions. Compare shows, teams, and seasons to find practices that deliver the most lift. Publish dashboards that show trends and wins so crews see the value of clean tags. With numbers on the board, you protect budget and expand programs.
Search time saved per user and per team
Measure how long editors spend finding assets before and after enrichment. Break down by role and project to see where the biggest wins live. Tie time saved to hourly rates and overtime avoidance to show dollars saved. Use Google-style search analytics to study relevance and zero-result rates. When teams see time come back, they support the process.
Reuse rate, clip lift, and library activation
Define reuse rate as the share of assets that feed a second use such as a promo or social cut. Track clip lift by views, watch time, or conversions on repurposed material. Monitor library activation by title or franchise to see which back catalogs respond best. Use those insights to guide shoots and packaging that pay off. A living library beats a dusty archive.
Captioning speed, QC pass rate, and error reduction
Count how many minutes of captions you finish per hour of review and watch that number rise with better ASR. Track QC pass rates on captions, loudness, and colorspace to see where metadata helps most. Record error types and volumes so you fix root causes, not symptoms. Share fewer emergency fixes and weekend calls as a quality metric. When errors drop, morale rises. For deeper context, read our explainer on FCC caption rules for TV and streaming.
Implementation playbook for U.S. media teams
You fix metadata with a plan, a pilot, and a rollout that respects how shows work. Audit what you have, pick a series to prove value, and write playbooks people can follow. Train reviewers and admins, then scale by show or franchise so wins stay visible. Keep governance simple and enforceable. This playbook turns theory into delivery.
Audit current tags, debt, and schema gaps
Start with an inventory of current fields, taxonomies, and actual usage. Compare how editors search with the labels they get back to spot mismatches. List debt such as missing IDs, broken lineage, and fields no one updates. Rank fixes by impact and difficulty so you chase the right wins first. Share findings with creative leads to build buy in before you change tools.
Pilot on one series or season before scaling
Pick a show with champions and a steady schedule. Apply ASR, vision, and OCR with clear thresholds and reviewers on deck. Measure time saved, error rates, and reuse after six weeks. Hold a retrospective, capture what worked, and tune the schema and thresholds. With proof in hand, expand with confidence.
Train models and reviewers with clear playbooks
Create short playbooks with screenshots and examples for editors, producers, and reviewers. Include the tag list, decision rules, and common traps that slow people down. Schedule refreshers at season start or onboarding so habits stick. Track participation and show leaders who completes training on time. People perform better when expectations stay clear.
Roll out by show or franchise, not by department
Shows carry identity, deadlines, and budgets, so roll out where work lives. Equip one show at a time with the stack, schema, and review process from the pilot. Capture results, celebrate wins, and let that team mentor the next one. Departments then inherit a working pattern rather than a policy memo. This approach respects production reality and keeps momentum high.
Where Digital Nirvana improves production metadata accuracy
Digital Nirvana helps content teams raise accuracy and speed without manual drag. Our Metadata Application stack covers AI tagging, speech to text, topic and entity enrichment, and OCR tuned for broadcast and streaming workflows. We integrate with MAM, PAM, newsroom, and compliance tools, and we support sidecars, DocumentInfo, and edit decision lists. Our reviewers work inside user interfaces that match broadcast and streaming timelines. With Digital Nirvana, metadata becomes a product you can measure and improve. For an overview of monitoring best practices, browse our post on broadcast compliance recording.
AI tagging, transcription, and entity enrichment services
We combine high quality ASR with domain vocabularies so captions and transcripts start clean. Our enrichment adds topics, entities, and timecoded moments that help editors find scenes fast. We tune face, logo, and object detection to your shows and set rules that reflect your risk profile. Reviewers correct edge cases inside simple tools that learn from every decision. Accuracy rises while review time falls.
Integrations with MAM, PAM, newsroom, and compliance tools
We connect to common platforms through APIs, sidecars, and event webhooks so data flows both ways. When editors add markers, our services read them. When our services add tags, your systems see them. We respect IDs and schema to protect lineage and avoid duplicates. Our team collaborates with your engineers to test each integration across server, storage, and web application layers.
Review workflows that match broadcast and streaming timelines
Our review queues and thresholds support live, fast turn, and long form schedules. We set confidence rules, reviewer roles, and escalation paths so approvals land on time. Dashboards show throughput, error types, and model lift so producers steer in real time. We help you set SLAs that leaders accept and we staff to meet them. The workflow becomes part of making shows, not a bolt on chore.
Future trends in production metadata you can act on now
Metadata keeps evolving from labels to connected knowledge. Knowledge graphs link people, places, storylines, and outcomes across seasons. Generative summaries turn transcripts and detections into first draft logs and synopses. Standardized interchange across vendors reduces lock in and speeds collaboration. You can adopt each of these trends in steps.
Knowledge graphs to connect people, places, and moments
Knowledge graphs map relationships between entities such as characters, teams, venues, and themes. Editors then search by connections, like every moment two rivals meet at night in a stadium. Producers see arcs across seasons and plan promos around real patterns. Rights and sponsorship teams check obligations across related assets in one place. A connected dataset gives editors leverage without friction.
Generative summaries to speed logs and synopses
Generative tools digest transcripts, detections, and markers to write first draft logs and synopses. Reviewers adjust with clear controls so nuance stays intact. Teams publish faster because they start from structure rather than a blank page. Over time, the system learns tone and style to reduce edits. You gain speed without sacrificing voice.
Standardized interchange to cut vendor lock-in
Open, documented formats for timecoded detections, captions, rights notes, and catalog data let tools swap without friction. Vendors that support standards compete on quality instead of access. Integrations take days instead of months. You also keep leverage when contracts change because your data moves with you. Standards keep focus on storytelling and delivery.
Partner with Digital Nirvana to deliver accuracy at scale
At Digital Nirvana, we help you turn metadata into measurable ROI with products that fit your stack. Use MetadataIQ to enrich assets with timecoded markers that your PAM and MAM understand on day one. Pair it with MonitorIQ for searchable compliance archives and instant evidence. Speed caption work with TranceIQ and keep regulated deliverables on spec with our closed captioning services. Our services team writes the templates and playbooks so your reviewers work fast and your KPIs move in the right direction.
In summary…
This summary distills the playbook you can put to work today. Use it to align teams, pick your pilot, and track the metrics that matter. Keep language simple, schema documented, and feedback loops active. Treat metadata as a craft and a product, and accuracy will follow.
- Why accuracy matters
- Better findability saves hours for editors and producers across data sources and storage.
- Clean rights and consent data reduce takedowns and improve admissibility.
- Reuse and clip activation turn the library into revenue with clear production format notes.
- Better findability saves hours for editors and producers across data sources and storage.
- How workflows and AI connect
- Capture on set, validate at ingest, enrich in edit, and finalize in finishing.
- AI adds ASR, vision, OCR, and shot detection at scale.
- Event updates keep MAM, PAM, NLE, newsroom, and web application tools aligned.
- Capture on set, validate at ingest, enrich in edit, and finalize in finishing.
- What to design up front
- A schema with standards, IDs, Datatype choices, and rights fields that people understand.
- Multilingual tags, synonyms, and controlled vocabularies that reflect real use.
- Lineage and sidecars for traceability from ingest to master and archive preservation.
- A schema with standards, IDs, Datatype choices, and rights fields that people understand.
- How to keep accuracy high
- Human review with tuned thresholds and expert queues.
- Benchmarks on real show data, plus rotation of training sets for seasonal shifts.
- Privacy controls for PII, retention, and access audits.
- Human review with tuned thresholds and expert queues.
- Where to start
- Audit labels and gaps, then pilot on one series with champions.
- Train reviewers and models with lightweight playbooks and templates.
- Roll out by show or franchise, and publish KPIs that prove value.
- Audit labels and gaps, then pilot on one series with champions.
The payoff shows up in fewer re-shoots, faster captions, safer rights, and a library that works harder. With the right schema, pipeline, and partner, AI raises production metadata accuracy and gives your team time back.
FAQs
What does production metadata include in a modern workflow?
Production metadata includes technical fields like timecode, reel IDs, color space, and server paths, plus creative fields like scene, shot, take, and character. It also captures rights, consent, and usage notes that drive legal clearance and distribution. Many teams track Email, ESI, and DocumentInfo for PDF Files and spreadsheets created during production. Good schemas link all this to asset and version IDs so systems follow lineage. With that coverage, editors and producers work faster.
Which metadata types matter most and how do they differ?
Think in layers across the metadata spectrum. System metadata describes the file and storage layer such as size, Datatype, and file system data. Content metadata describes what appears on screen such as speakers, places, and logos. Business metadata ties assets to campaigns, markets, and goals. Together, these metadata types keep data structure clear and make search results more relevant.
How do we avoid common metadata issues during ingest?
Set a template for folder names, IDs, and sidecars. Validate inputs at ingest, not in edit. Normalize timecode, color space, and naming, and run disk metadata collection to capture provenance. Store a system metadata file and creation metadata for each item, and keep the crosswalk to exchange formats. Small steps early prevent big fixes later.
How does AI improve metadata accuracy without extra burden on crews?
AI handles repetitive tagging at scale while humans review edge cases. You set thresholds that favor precision for risky tasks and recall for discovery. Reviewers correct errors and confirm good calls, which trains models for next time. Benchmarks and refresh cycles keep models current with new shows and styles. This setup gives speed and control at once.
How does Digital Nirvana support accuracy goals without changing our stack?
Digital Nirvana integrates with common MAM, PAM, newsroom, and compliance tools to read and write metadata where you already work. Our services add ASR, enrichment, and detections with sidecar support and event updates. We align with your IDs and schema so lineage stays intact, and we design reviewer workflows that meet deadlines. Dashboards show throughput, error types, and lift so you steer quality. You gain accuracy and speed without a rip and replace.