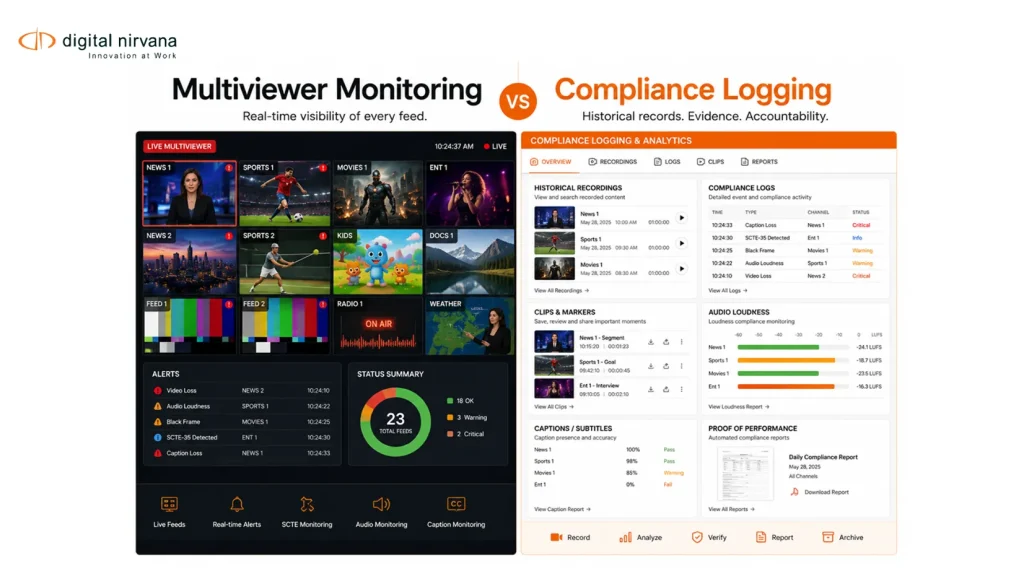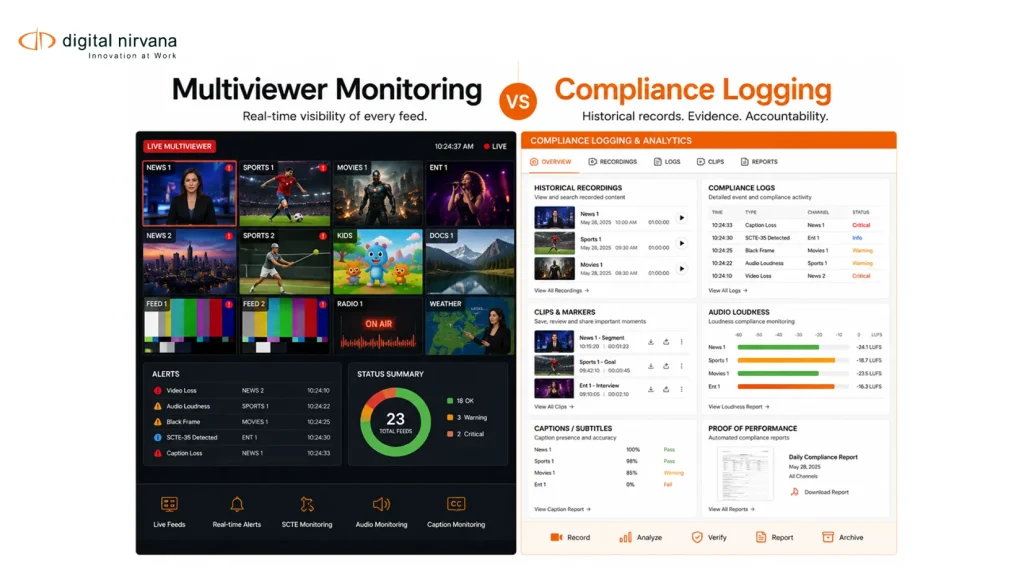
Video has really taken over everywhere, from broadcast TV to OTT platforms and social media channels. People watch 85% of social platform videos without audio, which makes on-screen text the primary means of communication rather than a secondary element.
Although visuals and sound really do tell the story, another very important layer is hidden within the video text that appears on-screen. This is exactly where Digital Nirvana’s video OCR software and on-screen text extraction technologies are making a real difference.
By converting video text into structured, machine-readable data, organizations can unlock a whole lot of useful insights, make their content more accessible, and greatly improve how easily others can find it
Why On-Screen Text is Important in Video Content?
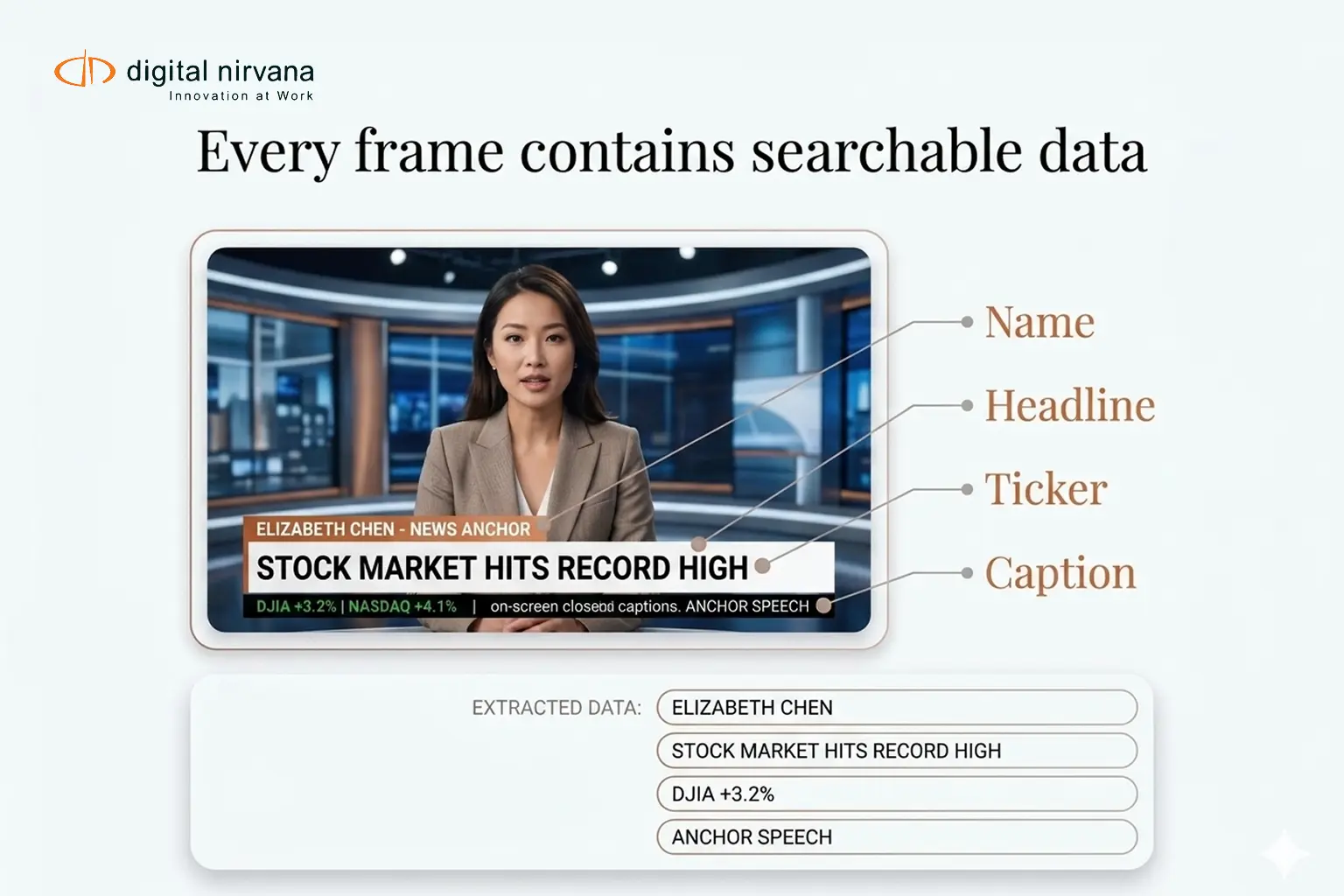
On-screen text plays a major role in how information is delivered in video. This includes lower thirds, chyrons, and financial tickers. For broadcasters and media teams, this information is often just as important as the audio, providing the important data intelligence required to categorize assets for high-speed retrieval.
This includes:
- Lower thirds showing names and titles
- Chyrons displaying breaking news or updates
- Captions and subtitles
- Financial tickers and data overlays
- Compliance disclaimers
For broadcasters and media teams, this information is often just as important as the audio.
Search Limitations for Lower Thirds and Chyrons
Without on-screen text extraction, teams face several limitations. Text inside videos cannot be searched directly, and manual review is required to locate specific information. This is particularly difficult for specialized fields like investment research, where on-screen financial data must be indexed for compliance and rapid analysis.
- Text inside videos cannot be searched directly.
- Manual review is required to locate specific information.
- Important metadata is missed or not captured.
- Compliance tracking becomes difficult.
- Archival content remains underutilized.
Even if a digital asset management DAM system is in place, it cannot access visual text without OCR capabilities.
What Is Video OCR Software?
Video OCR software uses optical character recognition to detect and extract text from video frames.
Instead of relying on captions or transcripts, it scans each frame and identifies visible text elements. This capability is a key feature of a modern managed AI strategy, converting visual text into searchable metadata with a timestamp.
Key capabilities include:
- Detecting text in lower thirds and overlays
- Extracting multilingual on-screen text
- Converting visual text into searchable metadata
- Indexing extracted text with timestamps
This enables organizations to search for video content based on what appears on-screen.

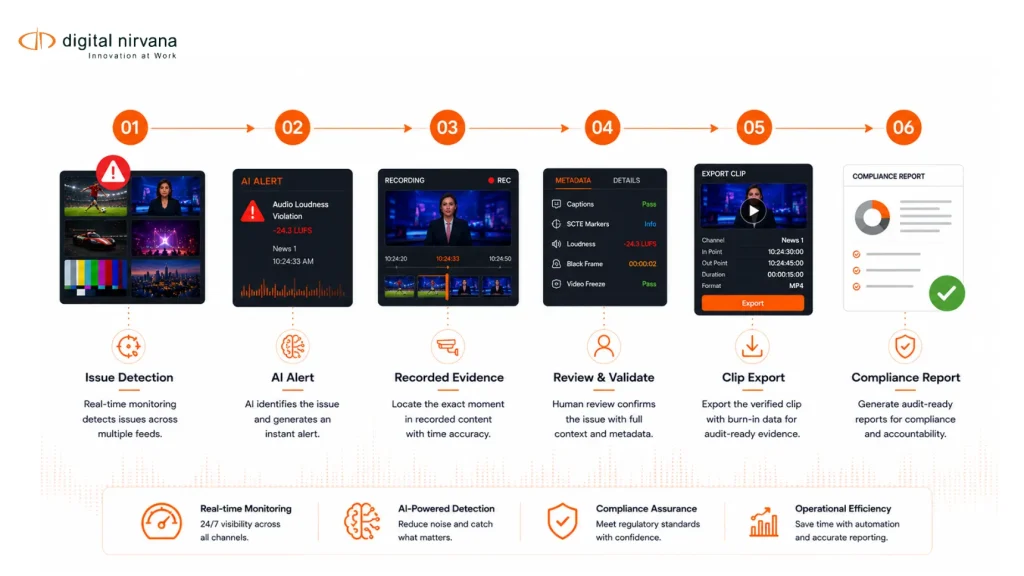
How Does On-Screen Text Extraction Work in Video?
The process typically involves several steps:
- Frame Analysis: Video is broken down into frames for detailed scanning.
- Text Detection: The system identifies regions in the frame that contain text.
- Character Recognition: OCR models convert detected text into readable data.
- Timecode Mapping: Each extracted text element is linked to a specific timestamp.
- Metadata Indexing: The extracted data is stored as searchable metadata.
This allows teams to quickly locate specific information, a task vital for managing content in digital learning management systems, where educational cues are often presented visually.
How MetadataIQ Enables Video OCR At Scale?
Digital Nirvana offers advanced media intelligence through its MetadataIQ platform.
With the MetadataIQ Media Indexing PAM MAM solution, video OCR software is integrated into a much wider media indexing workflow.
This enables organizations to:
- Extract on-screen text from lower thirds and chyrons automatically.
- The associate extracted text with quite precise time codes.
- Combine OCR data with speech-to-text and visual recognition results.
- Search across multiple metadata layers in one interface.
This unified approach really makes content much easier to find, analyze, and reuse. This enables organizations to search across multiple metadata layers in a single interface, all supported by enterprise-grade cloud engineering to handle enormous workloads.
How Media Teams Use Workflow Solutions?
Media teams use workflow solutions like MetadataIQ to streamline content discovery, ensure compliance, and maximize the value of video assets.
- News And Broadcast Archives
Journalists and producers can quickly find clips by name, location, or headline shown in the lower thirds.
- Compliance And Monitoring
Organizations can track disclaimers, regulatory text, or required on-screen information across content.
- Content Repurposing
Teams can locate specific moments using on-screen text and reuse clips for digital or social platforms.
- Media Analysis
On-screen text extraction helps in analyzing trends, topics, and recurring themes in video content.
By integrating intelligent workflows, media teams can move faster, work more efficiently, and unlock deeper insights from their content.
The Strategic Impact of Video OCR on Digital Asset Management
Integrating video OCR software into a DAM system, like MetadataIQ, improves how content is managed and used.
It helps organizations:
- Reduce time spent searching for video segments.
- Improve metadata accuracy and depth.
- Unlock value from archived content.
- Strengthen compliance tracking
- Enhance collaboration across teams.
Instead of relying solely on manual inputs, teams gain access to automated, structured insights.
Video OCR and Lower Third Detection with Digital Nirvana
Video OCR and Lower Third Detection act as a high-speed scanner for your visual content, instantly converting burnt-in text, name straps, and news tickers into rich, indexed metadata. By integrating these AI layers, you eliminate manual logging and ensure that every person identified and every headline displayed becomes a searchable data point in your DAM, making your entire library instantly navigable.
Some key features are:
- Frame-by-frame text detection: The system checks every frame of a video so that no text element is left behind, even in super-fast action scenes or transitions.
- Very accurate character recognition: Advanced algorithms can identify text with high precision, even under challenging conditions such as low resolution, motion blur, or complex backgrounds.
- Time-coded text extraction: Each text element we find is stamped with super-precise timestamps, letting users pinpoint exactly when and where the text appears.
- Support for many languages: AI models can read and process text in multiple languages, making them ideal for global media operations.
- Dynamic text detection: Scrolling tickers and moving text elements are captured and processed effectively, ensuring a complete job.
Lower-third detection further improves this process by specifically identifying the structured overlays you often see in broadcast content. This lets us categorize and index information like names, titles, and headlines much more accurately.
FAQs
It’s the process of extracting visible text from video frames using Optical Character Recognition (OCR) technology, then converting it into a format we can actually search.
Absolutely, current video OCR software is set up to find and extract text from overlays like lower thirds, chyrons, and captions itself.
Accuracy will depend on the quality of your video, how clearly fonts appear, and the contrast of your background – but even so, modern systems offer very high reliability for almost all kinds of broadcast content.
MetadataIQ combines OCR with timecode indexing and other metadata layers, making extracted text very easy to browse and get started with.
Yes, it is especially valuable for archives, where manually tagging everything isn’t even practical, and searchability is pretty limited.
Conclusion
On-screen text is a critical part of video content, but without the right tools, it remains difficult to access and use.
Video OCR software changes that by turning visual text into searchable metadata. When combined with timecode and intelligent indexing, it allows teams to find exactly what they need without reviewing hours of footage. Digital Nirvana provides the essential AI-driven tools needed to transform your “dark” video data into a fully indexed, revenue-generating media library.
Key Takeaways:
- Video OCR software automatically extracts on-screen text, transforming video into neat, structured, and fully searchable data.
- Lower-third detection really does improve our ability to capture critical contextual information, such as names, titles, and headlines, with absolute precision.
- Real-time processing allows organizations to monitor live broadcasts and respond super quickly to emerging trends or issues.
- Integration with a digital asset management DAM system greatly improves how we organize, retrieve, and work together on our content, all across various teams indeed.
- Onscreen text extraction makes your content much, much easier to find, so you can locate all sorts of specific information within even really large video libraries itself.
- AI-powered metadata solutions really do improve our compliance monitoring, ensuring we follow all relevant regulations and protect our brand’s reputation at all times.
- Combining OCR with technologies such as logo-detection software and speech-to-text creates a powerful, multilayered content intelligence system.