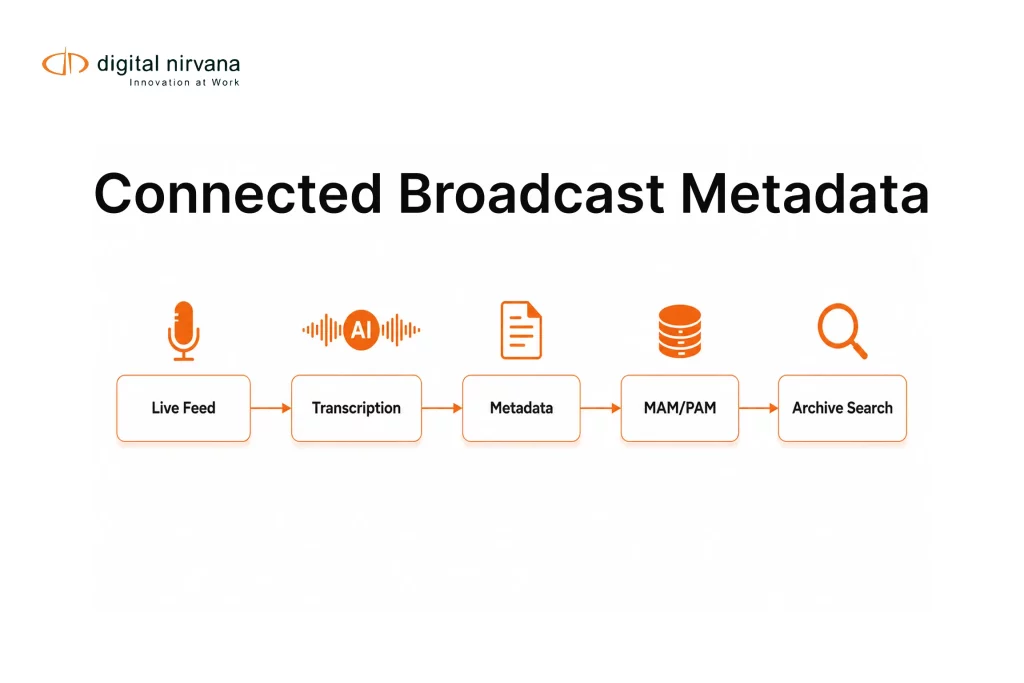
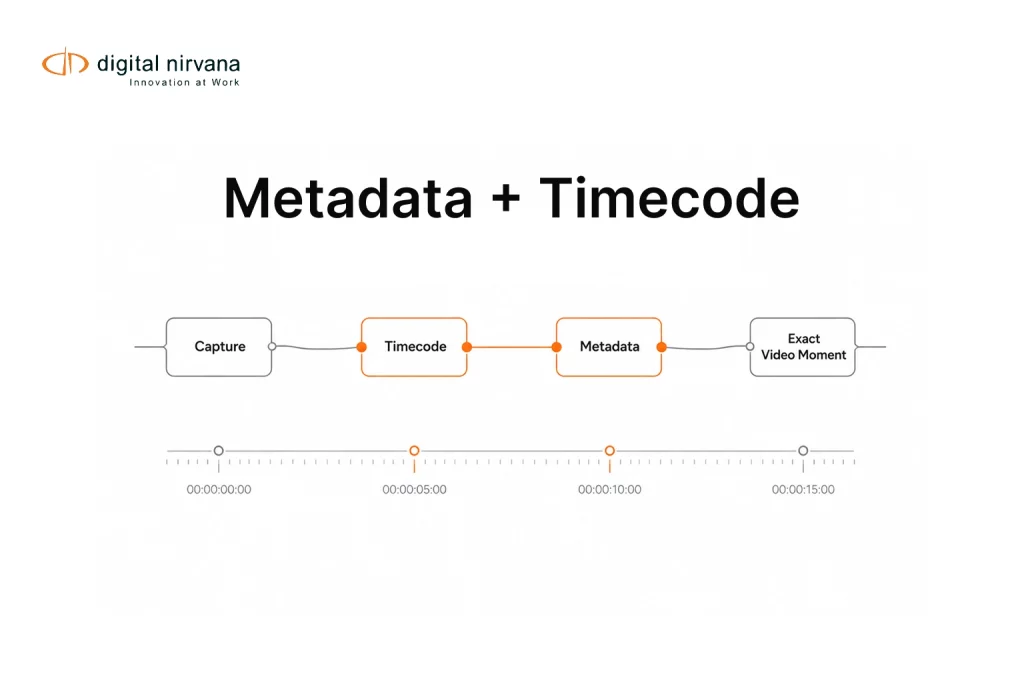
If two metadata tagging tools both claim “high accuracy,” you still do not know which one will save editors time, reduce missed moments, and keep search trustworthy.
What matters in real workflows is whether results are correct, usable, and consistent. A tool that occasionally tags the wrong person, suggests irrelevant topics, or drops timestamps will create more work than it removes. That is why an accuracy bake-off should look less like a marketing comparison and more like a controlled evaluation, with a gold standard, a scoring method, and a clear plan for analyzing false positives.
This guide walks through a practical bake-off process designed for broadcast, news, and sports libraries, including timecode search requirements and operational scoring.
What An Accuracy Bake Off Should Prove
A strong bake-off answers three questions that matter to production teams and stakeholders.
Does It Find The Right Things
This is your quality question, usually measured with precision and recall. Precision improves as false positives decrease. Recall improves when misses go down.
Does It Put People At The Right Moment
In media workflows, a tag that is technically correct but lands on the wrong timestamp can still be unusable. If your team relies on timecoded or timestamped transcripts to jump directly to moments, your bake-off must score timestamp alignment, not just the presence of a keyword.
Can It Hold Up Operationally
Even the best model fails in practice if it is slow, hard to integrate, or inconsistent across content types. Your bake-off should include throughput, latency, and integration readiness, in addition to accuracy.

Build A Gold Set That Reflects Real Media Work
A gold set is a curated set of assets with “ground truth” labels, created by humans and used as the reference for scoring. In information retrieval and extraction, evaluation compares system outputs to a gold standard and reports performance using measures such as precision, recall, and F-measure.
Choose A Representative Sample
Avoid building a gold set from only clean studio footage. You want your gold set to match the content that stresses tagging tools.
Include a balanced mix of:
- News studio, field reporting, press conferences, and phone audio
- Sports live play, highlights, studio analysis, and crowd-heavy audio
- Different accents, noisy segments, and overlapping speakers
- Graphics-heavy segments, lower thirds, tickers, and score bugs
- Archives with older codecs and variable audio quality
- Multiple languages if your library requires it
A practical starting point for many broadcasters is 50 to 150 clips, then expand once your scoring is stable.
Define Annotation Rules Before Anyone Tags
Most bake-offs go sideways because “ground truth” is not consistent.
Write down rules for:
- What counts as an entity mention, and what does not
- How specific tags should be, for example, “NBA” vs “Basketball.”
- How to handle nicknames, abbreviations, and misspellings
- Whether partial matches count, such as a person’s name that overlaps the correct name but misses the full span
- Timestamp rules, including acceptable tolerance windows
If you use entity-style tagging, align your rules with standard entity evaluation metrics that score correct detections vs. false positives and misses.
Use Dual Annotation On The Hardest Clips
For your most important workflows, use two annotators and resolve disagreements. This improves reliability and prevents vendor disputes later.
Define Scoring: Precision, Recall, And Timecode Fit
“Accuracy” is often a weak metric for tagging because it can mask errors in imbalanced data. Precision and recall are more informative, especially when you care about false positives and misses.
Core Scoring Metrics
Use these as the foundation.
- Precision, of all predicted tags, how many were correct? This drops when false positives rise.
- Recall, of all true tags in the gold set, how many did the tool find? This drops when misses rise.
- The F1 score is a combined measure that balances precision and recall.
Timecode Fit Scoring For Media Workflows
If timecode search is a requirement, add one or both of these.
Timestamp Hit Rate
For each gold set moment, did the tool return a hit with a timestamp close enough to be usable?
Define a tolerance window based on workflow:
- Compliance and QC may need tighter alignment
- Search and skim may allow wider alignment
Digital Nirvana’s guidance distinguishes between timecode-anchored transcripts and timestamped transcripts, and the right choice depends on how frame-accurate the workflow needs to be.
Median Timestamp Error
For matched hits, compute the median difference between the predicted and gold timestamps. This is a simple way to compare tools based on moment accuracy.
A Practical Scoring Table
| Metric | What It Measures | Why It Matters |
| Precision | How many returned tags were correct | Controls false positives that reduce trust |
| Recall | How many true tags were found | Controls miss that hide content |
| F1 Score | Balance of precision and recall | Prevents optimizing one at the expense of the other |
| Timestamp Hit Rate | Whether the hits land near the right moment | Determines whether time-based search actually works |
| Median Timestamp Error | Typical time offset for correct hits | Predicts editor’s effort to reach the right moment |

Score False Positives By Severity, Not Just Count
In production environments, not all false positives are equal.
A false tag that suggests the wrong topic might be annoying. A false tag that identifies the wrong person, team, or sensitive subject can create reputational and compliance risk.
Create A False Positive Severity Scale
A simple scale that works well:
- Severity 1: Harmless noise, minor irrelevant tags
- Severity 2: Workflow drag, wrong sport, wrong team, wrong show, causes wasted time
- Severity 3: High impact, wrong person, wrong allegation context, rights-sensitive errors, creates risk
When you score, track:
- False positives per hour of content
- False positives by severity tier
- The top recurring false positive categories, such as faces, logos, on-screen text, or named entities
Digital Nirvana’s newsroom automation guidance explicitly calls out tracking false positives and false negatives by category, because that is where practical improvement comes from.
Compare Tools With A Simple Bake Off Scorecard
Once you have the scoring, you need a way to choose.
A Balanced Scorecard That Works For Commercial Decisions
| Category | Example Measures |
| Quality | Precision, recall, F1, timestamp hit rate |
| Timecode Usability | Median timestamp error, jump-to-moment success rate |
| Consistency | Performance by content type, noisy audio, field reporting, live sports |
| Operations | Processing time per hour, throughput, failure rate |
| Integration | API readiness, write-back into PAM or MAM, metadata mapping needs |
| Cost | Cost per hour indexed, storage and compute costs, support costs |
If you must weight categories, do it openly. For example, if timecode search is the core outcome, give timestamp hit rate and timestamp error more weight than generic tagging recall.
Run The Bake Off In A Way Vendors Cannot Game
Freeze The Gold Set And Rules Before Testing
Do not allow label definitions to shift midstream. Agree on:
- The taxonomy scope
- Allowed tag families
- Timestamp tolerances
- Output formats required
Use A Blind Holdout Set
Give vendors a smaller training or calibration set, then score them on a holdout set they have not seen. This reduces overfitting to your examples.
Require Raw Outputs And Confidence Scores
You want:
- The tags and timestamps
- Confidence scores
- Any hierarchical labels used
This allows threshold tuning and deeper analysis of why false positives happen.
Validate Real Search Behavior, Not Only Tag Counts
If your users search in MAM using transcripts and time-based markers, you should test:
- Whether searching for a phrase returns the right clip
- Whether clicking a hit jumps to the right moment
- Whether proxies and previews support fast verification
How MetadataIQ Fits Into Evaluation And Deployment
If your bake-off is aimed at improving findability inside PAM and MAM systems, the best outcome is not a standalone tagging report. It is metadata that appears where editors and producers already work.
Digital Nirvana positions MetadataIQ as a media indexing and PAM MAM integration solution, designed to generate time-based metadata and integrate it into production workflows for smarter retrieval.
FAQs
Metadata tagging tools automatically generate tags for media, such as people, topics, places, teams, on-screen text, and spoken words, so content becomes searchable and reusable.
A gold set is a curated set of clips with human-labeled ground truth, used to compare tool outputs and to calculate metrics such as precision and recall.
Track how many incorrect tags are produced, then categorize them by severity and type. Precision improves as false positives decrease, so precision is a direct indicator of false-positive control.
Measure the timestamp hit rate and timestamp error against a gold set of known moments. If your workflow needs precise edit points, score timecode alignment tightly. If your workflow is search-and-skim, score broader timestamp tolerances.
No. F1 is useful, but it can hide whether errors are mostly false positives or mostly misses. Report precision and recall together, then add timecode usability and operational scoring.
Conclusion
A metadata tagging tools bake-off works best when it is built around real workflows. Build a gold set that reflects newsroom and sports reality, score precision and recall, then add timecode fit so you are measuring what editors actually feel. Finally, treat false positives as a risk and trust problem, not just a number, and score them by severity.
Key Takeaway
- Build a gold set that matches your real content mix, including noisy audio, live sports, and field footage.
- Score precision and recall together, then use F1 as a summary, not a decision by itself.
- Add the timestamp hit rate and timestamp error if timecode search is required.
- Track false positives by severity and category, because that is what drives trust and adoption.
- Choose tools using a balanced scorecard that includes quality, usability, operations, and integration, so the winner performs inside your PAM and MAM workflows, not just in a demo.