For years, metadata was treated as an afterthought, something interns entered in spreadsheets, something only archivists cared about, something that could always be “fixed later.”
That era is over.
Today, every part of the media business runs on metadata
- Search and discovery inside Avid and your PAM/MAM
- Rights and compliance audits
- FAST and OTT packaging
- Dynamic ad insertion and sponsorship proof
- Personalization and recommendations
At the same time, content volumes have exploded. A single broadcaster might generate thousands of hours of content per month across linear, digital, social, and streaming. No human team can consistently label this.
The only realistic future is metadata automation at scale.
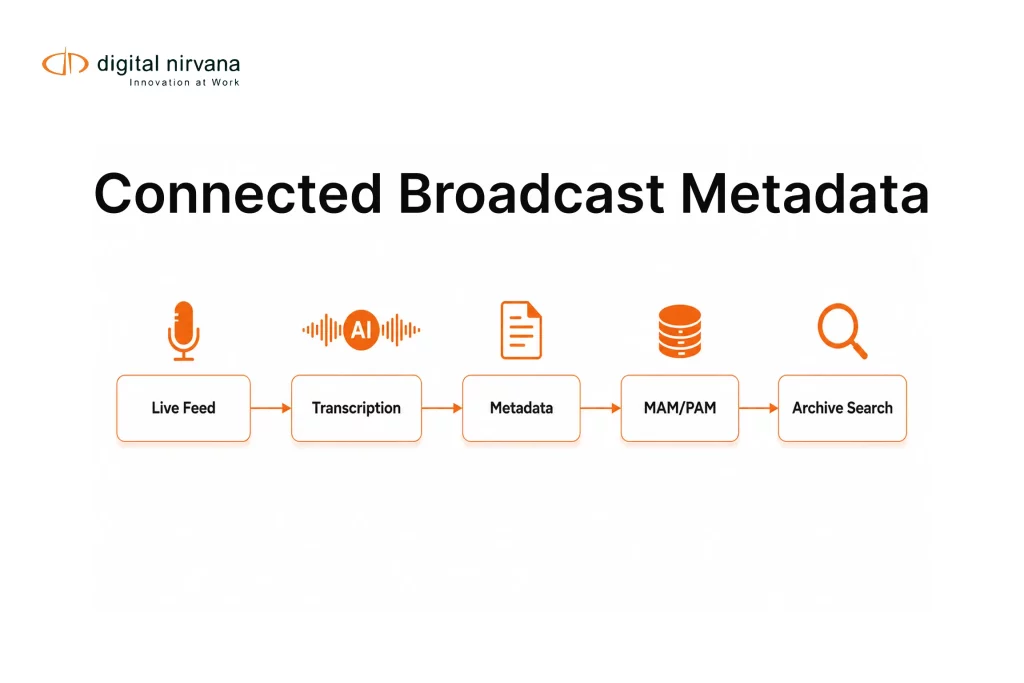
Digital Nirvana’s MetadataIQ sits squarely in this future: a SaaS-based metadata automation platform that uses AI and ML to generate speech-to-text and video intelligence, then pushes that metadata directly into Avid and other media workflows as time-coded markers and enriched fields. But this isn’t just a product story; it’s a structural shift in how media companies will operate.
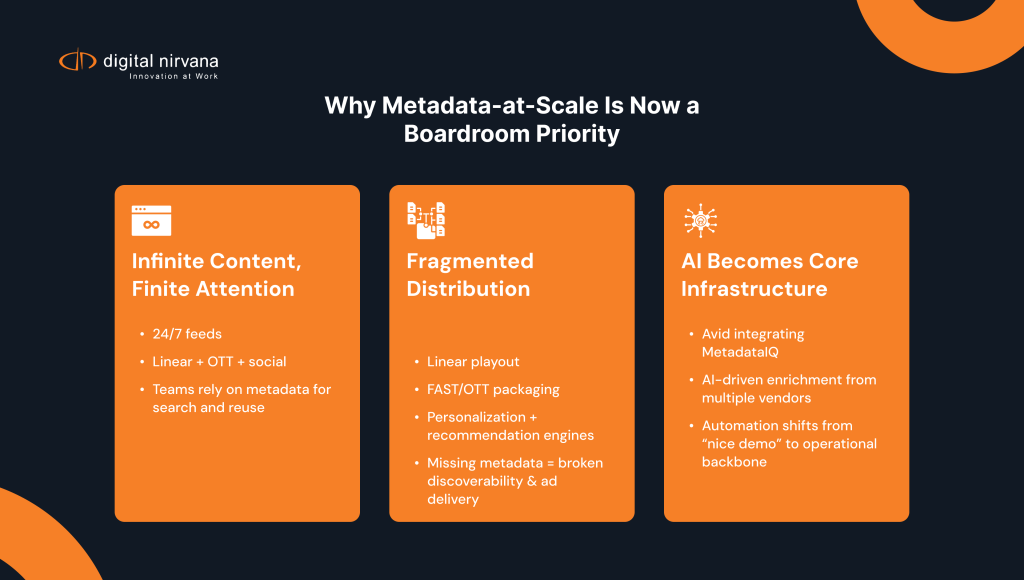
Why “Metadata at Scale” Became a Boardroom Issue
There are three converging realities:
1. Infinite Content, Finite Attention
News, sports, entertainment, streaming originals, FAST channels, and social clips content pipelines are now always on. Your teams cannot remember where anything lives; they rely on metadata to surface the right moments on demand.
The problem: legacy metadata practices were designed for hours per week, not thousands of hours per month.
2. Distribution is Fragmented and Metadata-Hungry
Every platform wants something slightly different:
- Linear playout needs clean rundowns and basic descriptors.
- Streaming and FAST need episode-level and segment-level metadata, SCTE markers, and rights windows.
- Recommendation engines need rich, contextual metadata to drive personalization and engagement.
If metadata is missing or shallow, you feel it in real metrics: low discoverability, weaker watch-time, broken ad campaigns.
3. AI is Moving from “Nice Demo” to “Core Infrastructure”
The broader industry is shifting rapidly toward embedded AI metadata engines:
- Avid is showcasing MetadataIQ as part of its AI and automation story for MediaCentral and Media Composer.
- Vendors such as Telestream and ThinkAnalytics are introducing AI-driven metadata layers to enrich archives and personalize content.
This isn’t hype; it’s how media platforms stay competitive. The organizations that treat metadata automation as infrastructure will move faster and monetize more of what they already own.
Manual Metadata Was Never Designed for This Scale
Let’s be blunt: even the best manual logging teams can’t keep up.
Manual-only approaches break down when:
- Feeds run 24/7 across multiple channels and regions
- Archives span decades with inconsistent descriptors
- New distribution deals demand new metadata fields “yesterday”
- You need to answer complex questions quickly:
- “Find every on-air mention of this brand in the last 18 months.”
- “Show me all segments involving this politician across all shows.”
- “Pull every instance of this logo across all sports rights.”
You end up with:
- Inconsistent tags (different people describe the same thing differently)
- Metadata debt (huge backlogs that no one has time to fix)
- Missed opportunities (content that never gets reused because no one can find it)
This is precisely why Digital Nirvana has been advocating for “autometadata” AI-driven metadata generation that augments and extends human work rather than trying to replace it.
What Metadata Automation at Scale Actually Looks Like
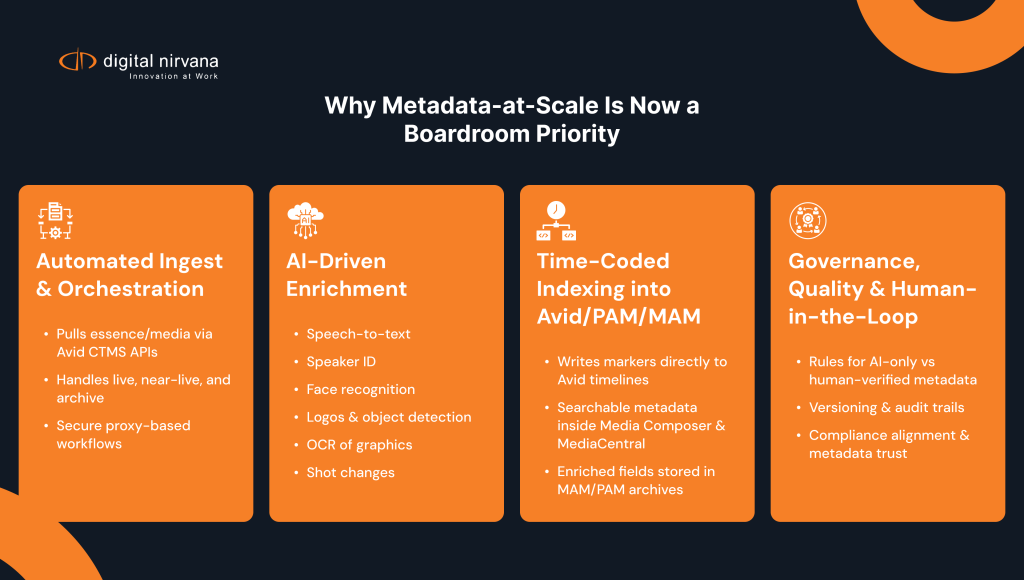
“Automation” is a broad word, so let’s make it concrete. At scale, metadata automation should cover four layers.
1. Automated Ingest and Orchestration
First, your metadata engine needs to connect directly to where your content lives:
- Pulling media or essence from Avid Media Composer / MediaCentral and other PAM/MAM systems via APIs
- Handling live, near-live, and archive assets without manual exports
- Managing proxies or audio derivatives securely where needed
MetadataIQ does this by integrating with Avid’s modern CTMS APIs and related services, so metadata workflows are triggered automatically when new assets appear, no spreadsheet, no watchfolders.
2. AI-Driven Enrichment (Speech + Vision)
Once the media is in scope, the automation layer should apply multiple AI models:
- Speech-to-text for transcripts and keyword search
- Speaker identification in news and talk formats
- Facial recognition for recurring personalities (talent, guests, athletes)
- Logo and object detection for sponsors, signage, and contextual visuals
- OCR to capture lower thirds, scorebugs, and on-screen text
MetadataIQ was explicitly designed for this multi-signal enrichment, turning each asset into a rich metadata object rather than just a video file.
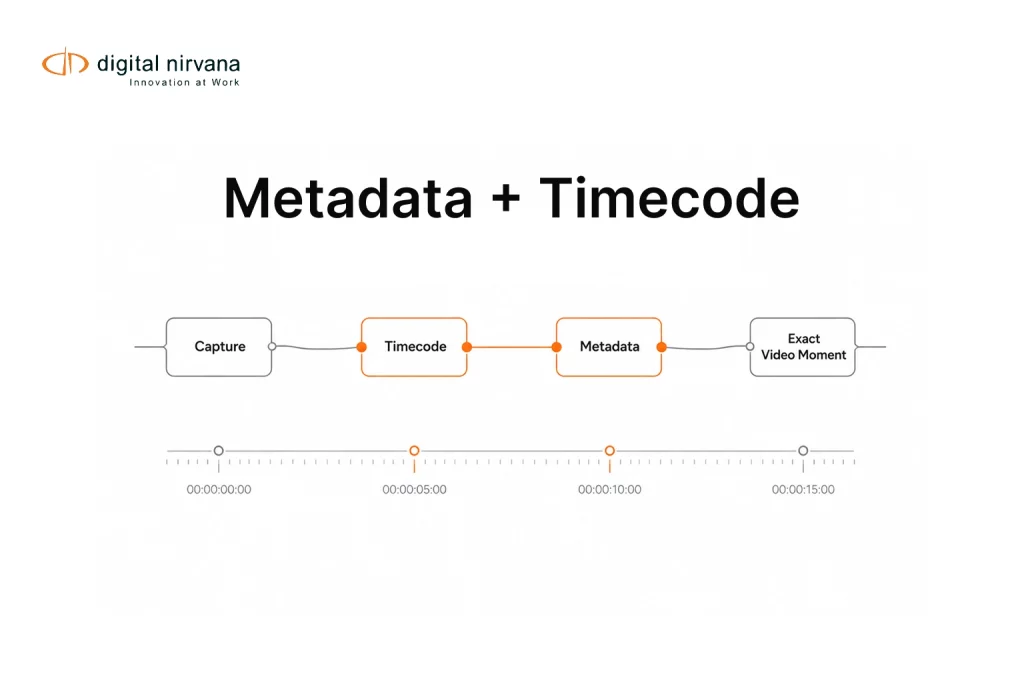
3. Time-Coded Indexing Back into Production
Automation at scale is useless if the results never reach the people who need them.
The key is time-coded, workflow-native metadata:
- Enriched data is written back into Avid as markers and fields that editors can see on the timeline.
- News and sports teams can search directly inside MediaCentral or Media Composer for people, topics, brands, and phrases.
- The same metadata flows into PAM/MAM and archive systems for long-term value.
This is where MetadataIQ stands apart from “generic AI tools”; it’s designed to live inside production rather than in a separate web portal.
4. Governance, Quality, and Human-in-the-Loop
Finally, automation at scale has to be governed, not just “switched on”:
- Policy-driven decisions about where you accept AI-only vs. where you require human review
- Versioning and audit trails for when metadata changes
- Alignment with compliance and rights teams so metadata can be trusted in legal and regulatory scenarios
Digital Nirvana’s heritage in monitoring and compliance workflows (MonitorIQ) gives the company a unique vantage point here: metadata can’t just be fast; it has to stand up to an audit.
The Future: AI-Native Media Workflows, Not “AI Add-Ons”
Looking ahead, the most crucial shift isn’t the individual model (today’s ASR vs. tomorrow’s foundation model). It’s the architecture.
Here’s where the industry is clearly heading:
1. Metadata-First Design
New workflows will be designed assuming that every asset carries rich metadata from day one:
- Journalists will pitch and build stories by searching concepts, not just shows.
- Sports producers will treat logs, stats, and video as part of one metadata fabric.
- Streaming teams will configure new FAST channels or curated rails by targeting metadata slices (“all election explainers under 5 minutes,” “all segments about this team with sponsor exposure”).
2. Real-Time Intelligence for Live and FAST
Real-time metadata will increasingly drive:
- Live rundown decisions (which feed to prioritize)
- Instant highlight generation and social clipping
- Dynamic ad insertion and campaign verification across linear and streaming
MetadataIQ already supports live and near-live content, generating transcripts and video intelligence as assets are created and pushing them back into Avid quickly enough to matter for breaking news and sports.
3. Cross-System, Cross-Vendor Metadata Fabric
No single vendor will own the entire stack. Instead, we’ll see:
- Interoperability between AI metadata engines, PAM/MAM, ad-tech, and recommendation platforms
- Shared schemas and APIs that allow metadata to flow where it’s needed without brute-force integration on every project
- More collaborations like the Avid–Digital Nirvana partnership, where metadata automation becomes a native feature of creative tools rather than an afterthought.
The winners will be the companies that treat metadata as a shared, strategic asset across departments, editorial, operations, legal, and business.
Where MetadataIQ Fits in This Future
Digital Nirvana’s public roadmap and messaging are already aligned with this direction:
- “All media. Every scene. Instantly searchable.” isn’t just a tagline, it’s the core promise of metadata at scale.
- MetadataIQ is positioned as the metadata automation backbone for Avid-based workflows and beyond.
- Recent updates add richer video intelligence, better integrations, and more scalable cloud processing, explicitly to support growing volumes and live workflows.
In practical terms, that means:
- You can start by automating metadata on one channel, one show, or one archive collection.
- You measure time saved in search, logging, and editing.
- Then you scale more channels, more teams, more use cases, without redesigning your workflows.
How to Start Building Metadata Automation at Scale (Without Boiling the Ocean)
If you’re staring at a massive archive or complex live operation, the idea of “metadata at scale” can feel overwhelming. You don’t have to do it all at once.
A pragmatic approach usually looks like this:
- Pick a High-Impact Use Case
- Faster sports highlights
- Quicker news package building
- Compliance and proof-of-performance for a key channel
- Define Success Metrics
- Time saved per story or package
- Number of clips reused from archive
- Reduction in manual logging hours
- Pilot with a Focused Metadata Automation Tool
- Connect MetadataIQ to your Avid or PAM/MAM
- Run a representative volume of content through it
- Compare workflow before/after in real terms
- Scale and Standardize
- Roll out to additional teams and channels
- Align metadata schemas and governance across departments
- Build new products (FAST channels, VOD collections, sponsor reports) on top of the enriched metadata fabric
The organizations that move now will have a structural advantage: richer data, faster workflows, and more ways to monetize content they already own.
FAQs: Metadata Automation at Scale
“Metadata automation at scale” means using AI-driven tools to generate and manage metadata for all your content live, near-live, and archive without relying on manual logging. Instead of people tagging only a small fraction of assets, a platform like MetadataIQ automatically generates speech-to-text, face/logo/object detection, and other time-coded metadata for every asset that passes through your Avid/PAM/MAM environment.
No. Metadata automation is most effective when it plugs into what you already have. MetadataIQ is designed to integrate with Avid Media Composer, MediaCentral, and other PAM/MAM systems via APIs. Your editors stay in the same tools they just see richer, AI-generated markers and fields on the assets they’re already working with.
Generic AI tools usually give you a standalone transcript or tag list and leave integration up to you. MetadataIQ is built specifically for media operations:
It pulls media directly from Avid / PAM / MAM
Runs multi-layer analysis (speech, faces, logos, OCR, etc.)
Writes everything back as time-coded markers and metadata inside your production systems
So instead of “here’s a file,” you get searchable timelines and assets in the tools your teams use every day.
No good automation augments those teams. AI handles the repetitive baseline work (transcripts, basic tagging, common faces/logos), and your specialists:
Define schemas and rules
Curate and correct metadata for premium or high-risk content
Focus on deeper context, rights, and editorial decisions.
The result is better coverage with the same or smaller manual effort, not a blind replacement of people with machines.
Common ROI indicators include:
Time saved finding footage or soundbites
Reduction in manual logging hours
Increase in archive reuse (more clips pulled from existing content)
Fewer missed obligations (easier proof-of-performance for sponsors and rights-holders)
Most teams run a short pilot: compare a few weeks of work with vs. without MetadataIQ and measure actual time and output differences.
Larger groups feel the pain first, but regional broadcasters, sports clubs, streamers, and even corporate media teams benefit once volumes rise. If you’re:
Producing content daily
Struggling to find things in your archive
Serving multiple platforms (linear + OTT + social)
…then metadata automation at scale is relevant, even if you’re not a “mega-broadcaster.”
Start small and focused:
Pick one use case (e.g., a flagship news show or a key sports property).
Connect MetadataIQ to your Avid / PAM / MAM for that scope.
Run it for a defined period and measure time saved, clips reused, and manual effort reduced.
Conclusion
Metadata at scale is no longer a “nice to have” it’s the operating layer that will separate agile, AI-native media organizations from everyone else. As content volumes grow and distribution becomes more fragmented, manual logging and patchwork metadata practices can’t keep up. The teams that win will be the ones that treat metadata as infrastructure: always on, deeply integrated, and trusted across editorial, operations, ad sales, and compliance.
MetadataIQ is built for exactly that reality. By plugging directly into Avid and PAM/MAM environments, applying multi-layer AI to every asset, and writing results back as time-coded, workflow-native metadata, it turns your existing systems into a more innovative, searchable, future-ready fabric. Instead of chasing files and rebuilding the same packages, your teams focus on storytelling, monetization, and rapid response across live, near-live, and archive content.
The path forward doesn’t require a “big bang” overhaul. It starts with a focused use case, clear success metrics, and a pilot that proves real-world gains in time saved, content reused, and obligations met. From there, you scale more shows, more channels, more teams on top of a shared metadata foundation. For media organizations that want to move faster, do more with the content they already own, and be ready for what’s next, metadata automation at scale and platforms like MetadataIQ won’t just support the future of workflows; they’ll enable it. They’ll define it.