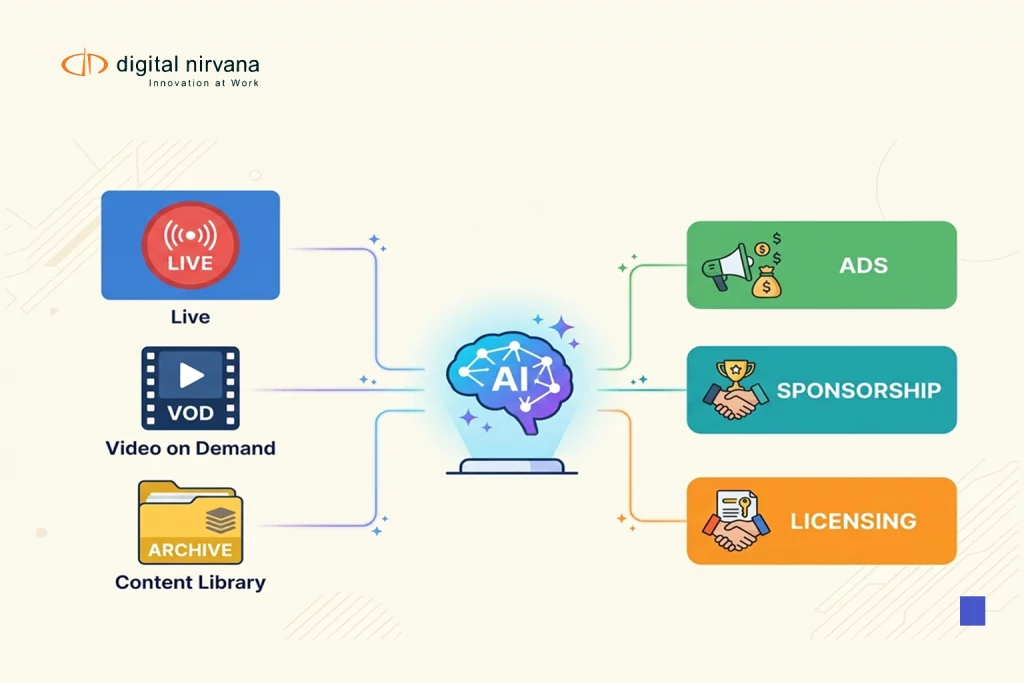
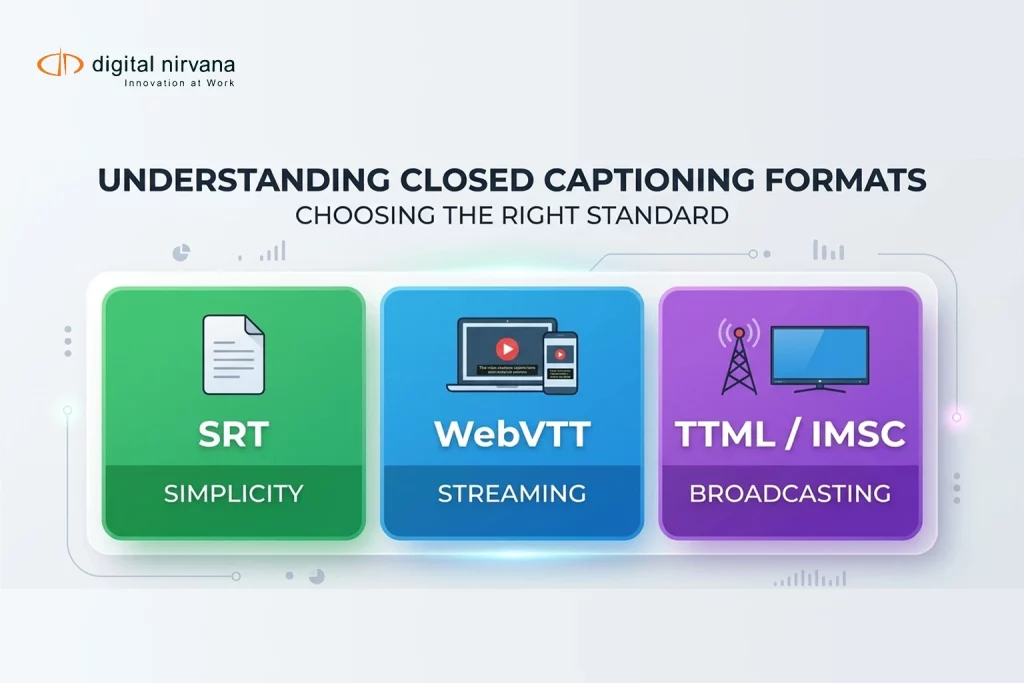
Newsroom metadata drives faster publishing, better search, and smarter reuse in every desk. Innovation now means clean metadata tags that your browser, CMS, and newsroom management tools can read without friction. Editors in The New York metro desk and bureaus across France, Denmark, India, and Wayne rely on the same metadata categories, keyword search, and content classification to cut time. Clips index on Google, LinkedIn, and even Wikipedia-style knowledge bases because news format, editing content discipline, and metadata understanding line up. You gain discoverability across the Globe while email alerts and algorithms keep producers thinking about the story, not forms. In 2026, newsrooms that invest in metadata win speed, quality, and revenue while teams focus on reporting Taylor coverage and civic beats.

What newsroom metadata means for speed, search, and revenue
A newsroom that treats metadata as a product ships stories faster, makes them findable everywhere, and monetizes them longer. Metadata describes the who, what, when, where, and why of each asset, so every system can route, sort, and showcase content without guesswork. Reporters gain time because the right clip surfaces while they write, and producers avoid duplicate effort because search returns the best version first. Sales teams book safer campaigns because categories, topics, and brand flags steer ads to suitable segments. Strong metadata cuts friction from pitch to publish and turns the archive into a profit center.
Descriptive, structural, and rights metadata explained
Descriptive metadata names the content and context, such as titles, summaries, beats, topics, and entities like people and places. Treat these as metadata categories made up of specific metadata items and metadata tags that match how your desks work. Structural metadata covers the functionality of how to assemble the piece, including shot lists, segment markers, captions, and relationships between packages, cuts, and promos. Rights metadata defines who can use the asset, on which platforms, and until what date, with embargo notes and license details that protect the newsroom. A newsroom that documents description, structure, rights, and news format at the start avoids rework, takedowns, and missed sales.
From rundown to archive, where metadata saves time
Metadata speeds the entire path from assignment to long-term storage. In the rundown, tags align scripts, b-roll, and graphics so control rooms call the right source on the first try. During edit, scene markers, speaker labels, and transcript timecodes jump you to the exact soundbite, which trims minutes from every sequence. In the browser or the NRCS, email notifications and newsroom workflow cues guide the right editor to the right asset in real time. At publish, platform fields push thumbnails, alt text, and schema so stories index well and look clean. In the archive, normalized vocabularies and IDs let producers pull past coverage in seconds, which turns anniversaries and follow-ups into quick wins.
How better tags lift SEO, syndication, and ad yield
Search engines reward clarity, so consistent keywords, keyword search intent, and structured data help your stories rank for the terms audiences already type on Google. Syndication partners depend on clean categories, topics, and entity IDs so their systems can map your feed without manual fixes. Clean tags improve discoverability on LinkedIn, OTT apps, and the open web, and they help ad tech place buys that meet brand safety. Sales teams connect contextual wins to historical AdWords and Google Ads benchmarks to prove lift without third-party cookies. More relevance drives more watch time, which leads to better fill and higher CPMs.
Our services at Digital Nirvana improve speed and discoverability
Our services at Digital Nirvana help your teams move faster without breaking routines. MetadataIQ auto-tags video, enriches PAM and MAM with timecoded markers, and keeps metadata categories consistent across desks. MonitorIQ records, indexes, and validates airchecks so standards, legal, and sales share the same source of truth. TranceIQ generates transcripts and captions that flow into CMS and OTT with clean rights data. MediaServicesIQ supports multilingual enrichment and quality checks across live and on-demand. Our approach stays empathetic, fact-based, and helpful, so editors see value on day one.
Why automated metadata extraction beats manual logging
Automation beats manual logs because it tags at machine speed, holds the same rules every time, and frees staff for journalism. Human loggers do high-value checks and edge cases, but they do not keep up with multi-hour feeds or overnight archives. Automated extraction gives every asset a baseline of transcripts, entities, and scene markers the moment it lands, so teams can focus on crafting the story. Consistency matters for search and analytics, and machines deliver consistent fields without fatigue. With automation in place, managers can measure real throughput from ingest to air and fix bottlenecks where they exist. For a field view of live workflows, explore our Metadata Solutions 2026.
Real-time tagging at ingest for faster time to air
Real-time pipelines listen to live feeds, generate transcripts, and attach tags while the story develops. Producers get searchable text and named entities during the briefing, which means they cut clips as quotes land. Control rooms see segment markers in the NRCS, so live switching and lower thirds come together without delay. Social teams pull pre-tagged excerpts for quick turnouts on platforms that reward speed. Real-time tagging trims minutes from breaking news and gives every desk the same early view of the facts.
Consistency across desks with fewer human errors
Automation enforces the same taxonomy across morning shows, digital desks, and weekend crews. The model will not spell a mayor’s name three ways or move a story between unrelated beats because of a shift change. With a controlled vocabulary behind the scenes, systems map tags to the same internal IDs, which keeps analytics clean. Editors still correct nuance, but they do it on top of a consistent base instead of mopping up typos. Fewer errors means fewer re-publishes, fewer takedown requests, and happier syndication partners.
Staff time reclaimed for reporting and editing
When machines handle first-pass tagging, humans spend time on interviews, source checks, and story craft. Reporters review suggested entities and add unique angles instead of typing lists into forms. Producers focus on sequences, graphics, and checks that lift quality, which helps ratings and trust. Managers reassign hours toward field reporting and enterprise work because the log sheet grind no longer eats the day. The newsroom wins speed and quality without burning out the team.
How AI-powered extraction actually works behind the scenes
AI pipelines turn raw media into structured data using a stack of specialized models and rules. Audio models convert speech to text and mark who spoke when, while text models find topics and entities. Vision models read on-screen text, logos, and scenes, and tie frames to the right moments in the transcript. Orchestration services stitch the results into one record that downstream systems can trust. The pipeline relies on tested algorithms and clear functionality so staff build real metadata understanding, not blind faith. For hands-on tactics, see our piece on media listening tools for broadcasters.
Speech-to-text, diarization, and keyword spotting
Automatic speech recognition converts audio to timecoded text at ingest, which makes the entire clip searchable. Speaker diarization separates voices and assigns labels, so you can jump to the mayor’s quote or the reporter tag without scrubbing. Keyword spotters watch for urgent terms like evacuation, recall, or indictment and trigger rundowns or alerts. These tools give producers quick handles on large files and reduce the chance of missing a critical line. When you align transcripts with metadata fields, you speed write-ups, captions, and compliance checks.
Entity recognition for people, places, and organizations
Named entity recognition scans transcripts and OCR results for people, places, organizations, and products. Good pipelines link those strings to a knowledge base, which resolves variations like POTUS, President, and the leader’s full name into one ID. Geocoding gives producers map-ready locations with coordinates that drive graphics and local SEO. Relationship extraction ties people to roles, events, and beats, which powers topic pages and backgrounders. For authority, systems cross-check entities against Wikipedia and match profiles on LinkedIn when policy allows.
Computer vision, OCR, and logo detection on video frames
Vision models detect scenes, faces, and objects, then match them with transcript moments to mark key beats. OCR reads chyrons, signs, documents, and social screenshots so that on-screen text becomes searchable and quotable. Logo detection tags brands for rights, sponsorship, and disclosure checks that protect the newsroom and its advertisers. Shot boundaries, motion cues, and visual similarity help editors find b-roll that matches scripts without hunting. With these tools, producers assemble packages faster and with more accuracy.
Summaries, topics, and sentiment from NLP pipelines
Summarizers generate tight abstracts that slot into CMS teaser fields without fluff. Topic models group related stories and power recommendation rails that keep viewers engaged. Sentiment analysis flags tone in UGC or political clips, which helps producers balance coverage and protect brand safety. Query expansion and embeddings improve internal search so staff can find the right context when speed matters. These NLP layers turn raw transcripts into editorial signals that move the newsroom faster.
Build a newsroom taxonomy that reporters will use
A taxonomy that fits the beat and the workflow keeps tagging simple and consistent. Reporters use vocabularies that match how they speak and write, and systems map those terms to IDs that machines understand. Keep top-level categories stable, then localize with desk-specific tags that still roll up cleanly. Give clear field definitions in the NRCS and CMS, and show examples so new staff learn fast. A good taxonomy reduces conflict between desks and raises search success across the board.
Align beats and desk terms with controlled vocabularies
Start with beats that never change like politics, public safety, education, and weather, then add regional slices for your market. Pull terms from IPTC or internal standards, and add newsroom examples so staff see the exact use cases. Write short, plain-English definitions that explain when to use each tag and when to skip it. Keep the list short enough to scan during a deadline, and push the rest into auto suggestions. When the beats and the vocabulary agree, editors tag without second-guessing.
Map synonyms, acronyms, and slang to a common ontology
Reporters say CHP, Highway Patrol, or state troopers and mean the same thing, so the system should map them to one concept. Build synonym lists and acronym expansions that link to a single ID, which keeps analytics and SEO clean. Add regional slang and community names that your audience actually uses, and connect them to the right entities. Use redirects in the CMS, so a mistyped tag still lands on the right concept page. With this map in place, your search logs get cleaner and your recommendation rails get smarter.
Keep labels tight to avoid tag sprawl
Short labels reduce disagreement and speed adoption. Limit free-text fields and prefer picklists or suggestions with a short list of approved options. Archive or merge tags that rarely see use, then track search misses to fill real gaps. Set up a quarterly review with desk leads who can trim noise and add only what proves value. A lean vocabulary delivers faster tagging and better analytics.
Standards that keep your metadata portable and future proof
Standards make your content move smoothly across partners, platforms, and years of storage. When you export clean, structured fields, new products launch faster and legacy systems do not block growth. Vendors can integrate without custom hacks because they recognize the same models and namespaces. Your archive also survives migrations because IDs and versions travel with the files. Standards protect your investment while you explore new formats and business lines.
IPTC NewsCodes and NewsML-G2 for news exchange
IPTC NewsCodes provide shared vocabularies for subjects, genres, and roles that every partner understands. NewsML-G2 packages content and metadata for exchange, which helps wires, affiliates, and platforms import your work without friction. Map your internal tags to these codes so you translate cleanly across systems while keeping newsroom language intact. When partners speak the same metadata language, you shorten onboarding and reduce errors. This base speeds syndication and lifts reach.
JSON-LD and schema.org for web and search engines
JSON-LD lets you embed structured data in pages so search engines and apps parse your stories with confidence. Use schema.org types for articles, videos, live blogs, and FAQs to represent the story you actually published. Add entities, dates, locations, and thumbnails with precise fields, not guesswork. These signals drive rich results and improve discovery across search, voice, and aggregators. Clean markup pays off in traffic quality and click-through rate.
Unique IDs and versioning for long-term archives
Assign a durable ID to every story, asset, and segment, and keep a version history that records edits and corrections. Link related items like web, OTT, and social cuts, so one concept holds the family together. Store rights and embargo changes with timestamps to manage compliance and re-licensing. When a story resurfaces, staff can verify the lineage and pull the right cut without hunting. Solid IDs and versions turn your archive into a trusted asset, not a mystery box.
Integrate automation with NRCS, MAM, CMS, and delivery
Integration turns metadata from a sidecar into the engine of daily production. Connect the pipeline to the NRCS for live control room cues, to the MAM for asset search and reuse, to the CMS for web and app output, and to delivery for OTT and social. The same tags carry through each hop, which keeps context intact. APIs, webhooks, and queues move updates in seconds so systems stay in sync. When everything talks, your newsroom acts like one team.
Real-time APIs and webhooks between systems
Real-time connections push transcripts, entities, and thumbnails as soon as models produce them. NRCS items receive updates during the show, and operators see clean labels for lower thirds and supers. The MAM indexes new clips without manual steps, which gives producers instant search. The CMS publishes with the right schema and canonical fields, and newsroom management tools send email alerts so editors act fast. These links remove delays that waste the day.
Batch enrichment for back catalogs at archive scale
Many archives hold decades of video and audio that never got proper tags, which means stories go dark. Batch enrichment jobs process libraries in chunks overnight, fill gaps with transcripts and entities, and add rights where contracts allow. Producers wake up to searchable backfiles that feed explainers, anniversary pieces, and evergreen packages. Sales gains inventory for brand-safe campaigns that need depth and history. The archive starts earning its keep instead of collecting dust.
Hybrid cloud pipelines for live and on-demand output
Hybrid designs run low-latency components near control rooms while heavy models scale in the cloud. Live shows get real-time cues without risking the rundown, and batch jobs scale up when big events hit. On-demand teams schedule enrichment when traffic allows, which keeps costs under control. Security teams keep sensitive feeds on-premises while still benefiting from cloud updates. This mix gives you resilience, speed, and efficiency.
Governance, privacy, and newsroom AI ethics
Strong governance keeps automation safe, fair, and compliant while the newsroom moves fast. Policies define what the system collects, who can see it, and how long it stays. Teams document model behavior, review outputs, and fix bias before it harms coverage or communities. Audit trails record changes so managers can investigate issues quickly and fairly. A clear framework builds trust with staff and audiences.
PII redaction and policy-based access controls
Pipelines should detect phone numbers, addresses, and other personal information and mask it when policy requires. Access controls gate sensitive fields so only the right teams can view or edit them. Retention policies remove data on schedule, and secure disposal procedures destroy expired files to reduce risk. Clear prompts and warnings in tools help staff make the right call at deadline speed. With guardrails in place, the newsroom protects sources and citizens.
Bias checks, audit trails, and human-in-the-loop
Run fairness tests on models with data from your market, not only generic sets. Track false positives and false negatives by category, and review edge cases with editors who know the beat. Keep humans in the loop for sensitive calls and publish guidelines that describe how decisions happen. Audit trails log who changed what field and when, so managers can coach and correct. These practices raise quality and keep trust intact.
Rights, embargoes, and usage restrictions in tags
Tag content with rights holders, embargo dates, and allowed platforms so systems enforce the rules. Attach license documents or IDs for quick checks during breaking coverage. Mark UGC with source, consent, and restrictions that protect the newsroom and the audience. Delivery systems read these fields and block unapproved uses without a scramble. Clear rights metadata keeps lawyers calm and shows advertisers you run a tight ship. For copyright guidance, consult the U.S. Copyright Office’s overview of fair use.
Measure ROI from metadata and newsroom automation
Leaders fund automation when they see faster cycles, higher output, and better revenue. Define KPIs that capture speed to publish, search success, reuse rate, and ad safety lift. Measure the hours staff reclaim from logging and the growth in stories that reuse archive footage. Track SEO wins with structured data and entity clarity, then connect those wins to traffic and revenue. A clean measurement plan turns metadata from a cost to a growth driver. For revenue levers, read Metadata Strategies for Content Monetization.
KPIs like time-to-publish, search success, reuse rate
Time-to-publish tracks minutes from ingest to web or air and shows real gains when automation lands. Search success measures how often staff find the right clip on the first try, which reveals taxonomy quality. Reuse rate counts how often a new story includes archive footage or prior reporting, a core signal of ROI. Add error rates for takedowns or re-publishes to capture quality improvements. Review these KPIs weekly and tie goals to beat-level dashboards.
Contextual ad targeting and brand safety gains
Contextual signals let ad servers place campaigns near content that matches buyer preferences without third-party cookies. Clean topics, entities, and sentiment give sales a credible brand-safety story that wins cautious budgets. Teams validate uplift against historic AdWords and current Google Ads data to keep claims grounded. Creative groups use metadata tags and metadata categories to build promos that drive the right segments. The revenue team sees metadata as the lever that supports both safety and scale. To keep compliance tight, review our overview of broadcast compliance recording and monitoring.
A simple cost-benefit model your CFO accepts
Finance leaders want a model they can test and explain. List costs for software, integrations, storage, and staff time, then estimate savings from reduced logging, faster edits, and fewer errors. Add upside from SEO, syndication, and contextual ad wins, grounded in your baseline data. Build scenarios for conservative, base, and stretch outcomes, and set checkpoints to course-correct. This model keeps spending honest and ties outcomes to metrics the business already tracks.
Inputs, benchmarks, and a payback calculator outline
Gather baseline inputs like average story minutes, ingest hours, error counts, and archive reuse per month. Use public benchmarks for ASR accuracy, entity precision, and processing speed, then adjust with pilot results. Create a simple calculator that takes hours saved, added revenue per thousand views, and error reduction to estimate payback months. Report monthly with real numbers so finance sees progress, not promises. When payback arrives, expand to new desks or deeper archives.
An adoption roadmap for American newsrooms
A clear roadmap helps leaders start small, learn fast, and scale what works. Pilot with one beat, publish results, and train staff using examples from their own stories. Build the taxonomy during the pilot and set review cycles that keep it sharp. Bring in IT and legal early so integrations and policies do not stall the plan. When the pilot proves value, roll out in waves tied to beats and shows.

Start with a pilot and gold-standard test sets
Pick a beat with steady volume and motivated editors, then gather a gold-standard set of clips with human-verified tags. Run the pipeline, compare outputs to the gold set, and track speed and accuracy against baseline. Share wins and misses in open forums so staff see honest progress and help improve. Use pilot insights to tune models and workflows before expanding to other desks. A strong pilot builds the case and teaches the team the new way of working.
Design the taxonomy and labeling guidelines
During the pilot, lock down field names, definitions, and picklists that match real stories. Write a short guide with examples that show correct tags and common mistakes. Put the guidelines in the tools where people tag, not in a PDF no one opens. Pair desk leads with product managers to approve changes and keep scope under control. Clear, visible guidance makes adoption stick.
Train desks, refine models, and scale by beat
Run short, hands-on sessions where reporters tag real clips with auto-suggestions turned on. Collect feedback in the moment and apply changes quickly so staff see impact. Expand to the next beat when the first one hits accuracy and speed targets. Keep a public scoreboard with KPIs and celebrate improvements, not only launches. This rhythm keeps momentum and proves value across the newsroom.
Common pitfalls and how to avoid them in 2026
Teams stumble when they add too many tags, ignore latency, or skip change management. Over-tagging creates noise that hides signal, while under-tagging leaves search blind. Latency surprises appear when models stack up without orchestration, and vendors lock you in if you skip open standards. Culture matters too, because editors will ignore tools they do not trust. Plan for these risks and you will save time and budget.
Over-tagging, under-tagging, and noisy vocabularies
A bloated vocabulary slows users and confuses models. Trim rarely used tags, and do not promote vanity labels that do not drive search or revenue. Add a field for other only when you review it weekly and convert common entries into real tags. Watch search logs for failed queries to discover real needs. Keep the vocabulary tight and your signals strong.
Latency surprises and vendor lock-in risks
Latency creeps in when you chain models without measuring end-to-end time. Profile the pipeline, parallelize steps where you can, and cache results for common assets. Use standards-based exports and keep your own IDs so you can switch vendors without re-tagging the world. Ask for clear SLAs on accuracy and speed, and negotiate exit terms before you sign. These safeguards keep control with the newsroom.
Change management across editorial and product
Editors adopt tools that solve their problems and respect their time. Include them in design sessions, show quick wins, and fix friction points within days. Celebrate desk experts who model good tagging and share tips across shifts. Product and engineering teams should publish roadmaps and release notes in plain English. When people feel heard and informed, they support the change.
Buyer’s checklist for automated metadata solutions
A practical checklist helps you compare solutions on signals that matter to editorial and business teams. Focus on accuracy and latency first, then on how the system explains itself and adapts to your beats. Evaluate customization, review tools, and integration depth so workflows stay smooth. Verify security, compliance, functionality, and total cost so the plan survives procurement. A good partner proves value in weeks, not quarters.
Accuracy, latency, and model transparency
Ask for precision and recall numbers on your content, not demo reels. Measure end-to-end latency at ingest, during live, and at publish, then set targets that reflect your shows. Demand transparency on training data sources, update cadence, and error modes so you know where the model works best. Require confidence scores and explainability features that help humans review quickly. These checks protect quality on air and online.
Customization, fine-tuning, and human review tools
You need models that learn your market, names, and beats. Look for custom dictionaries, prompt slots, or fine-tuning paths that your editors can influence without code. Require bulk review tools that let humans approve, reject, and correct suggestions at speed. Capture those corrections to retrain models and raise accuracy next month. Customization and feedback loops turn a vendor tool into your newsroom tool.
Security, compliance, and total cost of ownership
Confirm encryption in transit and at rest, with role-based access that fits your org chart. Review audit logs, retention policies, and data residency to match legal and union commitments. Price beyond licenses by including storage, egress, support, and staff time for change. Ask for a clear migration plan if you leave, including data formats and cost. A full cost picture prevents sticker shock and protects your schedule.
Where newsroom automation and metadata go next
The next wave blends video, audio, and text models, ties them into knowledge graphs, and pushes proactive assistance to desks. Multimodal models watch and listen together, which improves context and accuracy on mixed feeds. Vector search and retrieval-augmented generation pull the best background in seconds, then cite sources that editors can verify. Knowledge graphs link people, places, events, and timelines so stories gain depth with less effort. Smart rundowns suggest segments, guests, and clips as the day unfolds.
Multimodal models for video, audio, and text
Multimodal systems process frames and waveforms alongside transcripts, which raises accuracy on noisy pressers and field shots. These models learn cross-modal cues, like a name on a podium paired with a spoken line, and tag both correctly. Producers get stronger scene detection, better lip-sync checks for captions, and richer b-roll suggestions. The newsroom benefits from fewer misses and more confident automation. Multimodal pipelines set the baseline for 2026 and beyond.
Vector search, RAG, and knowledge graph enrichment
Vector search represents stories as embeddings, which means the system finds concept matches, not only exact words. RAG systems pull verified context from your archive into drafts and lower thirds, which speeds script writing and reduces errors. Knowledge graphs add relationships that power timelines, topic pages, and explainers without manual stitching. Editors see source links and can check facts before air, which protects trust. These tools raise both speed and quality.
Proactive alerts, recommendations, and smart rundowns
As models learn your beats, they flag emerging stories, surface related clips, and suggest guests with relevant backgrounds. Rundown tools propose segment orders based on audience interest and resource availability. Social teams get recommended cuts and captions that match platform trends without losing editorial judgment. Producers accept or reject suggestions with one click, and the system learns from those calls. Proactive help turns metadata into a daily partner, not a chore.
How Digital Nirvana supports automated metadata in news
Digital Nirvana helps newsrooms enrich content at scale with speech-to-text, captioning, and metadata services that plug into existing tools. Our teams integrate with your NRCS, MAM, and CMS so tags move with assets from ingest to archive. MonitorIQ delivers compliance logging and content discovery that support legal checks and editorial search. We offer deployment options for cloud, on-premises, and hybrid setups so you keep control and hit your latency goals. With Digital Nirvana, your staff spends more time reporting while the pipeline handles the heavy lifting.
Speech-to-text, captioning, and metadata enrichment
We generate accurate transcripts with speaker labels and deliver caption-ready files tied to timecodes. Our enrichment adds entities, topics, and summaries that drop directly into your CMS and MAM. Editors review suggestions in bulk and push approved tags into live rundowns and social posts. We tune dictionaries and models to your market so names and places land right the first time. Your team sees fewer fixes and more reuse.
Compliance logging and content discovery for publishers
MonitorIQ records and indexes broadcasts so legal and editorial teams can search, clip, and export in minutes. Brand safety and rights fields travel with the clips, which helps sales and standards review placements quickly. Producers pull prior coverage and compare air checks without waiting on engineering. The system stores audit trails for corrections and takedowns, which supports policy and trust. Compliance becomes faster and less painful. For regulations, see the FCC guidance on closed captioning of video programming.
Deployment options for cloud, on-premises, or hybrid
We support secure cloud for scale, on-premises for sensitive feeds, and hybrid when you want both. Real-time components sit close to control rooms, while batch enrichment scales elastically during big events. Our APIs and webhooks keep your NRCS and CMS in sync, so metadata lands where teams need it. We price with clarity and help you build a ROI model that finance can vet. The result pairs speed with control in a way that fits your operation.
At Digital Nirvana, we help you scale automation without chaos
At Digital Nirvana, we help you prove ROI quickly and scale by beat with clear milestones. MetadataIQ delivers consistent metadata items and dashboards that editors trust. MonitorIQ provides 24×7 compliance logging and fast clip export for ad verification and standards review. TranceIQ supports captioning and translation with timecoded outputs that your CMS and OTT pipelines accept. MediaServicesIQ offers scalable enrichment for live and on-demand so producers focus on the story.
In summary…
This summary wraps the core playbook and calls out how to move next with confidence. Metadata drives speed, discovery, and revenue when you capture it at ingest, standardize it across desks, and integrate it end to end. Automation sets a consistent floor that humans lift with judgment, while governance keeps the system fair and compliant. Measure what matters, train with real clips, and expand by beat as wins pile up. When you treat metadata like a product, your newsroom publishes faster and earns more.
- Start with one beat and a gold-standard test set, then measure time-to-publish, search success, and reuse.
- Build a tight taxonomy with controlled vocabularies, synonyms, and clear field definitions that reporters accept.
- Use standards like IPTC, NewsML-G2, and JSON-LD so partners and platforms import your work without friction.
- Wire NRCS, MAM, CMS, and delivery with APIs and webhooks for real-time and batch enrichment across assets.
- Protect privacy with PII redaction, access controls, and audit trails, and keep humans in the loop for sensitive calls.
- Track revenue impact through contextual ad gains, safer placements, and archive-driven packages that extend shelf life.
- Plan costs and savings in a model finance trusts, then reinvest savings into reporting and product.
Use this checklist to pick a pilot this month, set KPIs your leaders will accept, and connect the pipeline to one show. If you want a partner that knows news and ships working integrations, Digital Nirvana can help you move quickly without disruption. Let’s turn your archive into a daily asset and your live shows into smooth, searchable output.
FAQs
What is newsroom metadata and why does it matter
Newsroom metadata describes content so systems and people can find, route, and reuse it quickly. It covers descriptive fields like topics and entities, structural fields like segments and timecodes, and rights fields for usage. Strong metadata speeds production, improves SEO, and protects the brand with better ad targeting and compliance. Automation gives you a baseline set of tags for every asset, which humans refine for nuance. The result is faster publishing and higher revenue per story.
How accurate is automated tagging versus manual logging
Accuracy depends on models, training data, and the quality of your taxonomy. In practice, automation delivers consistent first-pass tags that humans beat on edge cases and sensitive calls. A combined approach wins because machines never tire and editors know context. Measure precision and recall against a gold-standard set from your own clips, then tune dictionaries and workflows. With feedback loops, accuracy improves month over month while speed stays high.
Which standards should a newsroom adopt first
Adopt IPTC NewsCodes for shared vocabularies and NewsML-G2 for content exchange. Add JSON-LD with schema.org for the web so search engines parse your pages. Assign unique IDs to assets and keep a version history so archives survive migrations. Map internal tags to external codes to keep newsroom language while exporting cleanly. With these standards in place, partners integrate faster and your content travels farther.
Can we start small without a full system change
Yes, start with one beat and connect ingest to the MAM and CMS for that desk. Run real-time extraction for new clips and batch enrichment for a small slice of the archive. Train the team, measure KPIs, and publish the results to win support for the next wave. Keep IDs and formats open so you can scale or switch vendors later. This approach proves value while risk stays low.
How do we justify the spend and show quick wins
Tie the plan to KPIs finance understands, such as time-to-publish, reuse rate, and error reduction. Track SEO lift from structured data and entity clarity and connect it to traffic and revenue. Show brand safety gains that help sales hold or raise CPMs without make-goods. Present a cost model that includes software, storage, staff time, and savings from reduced logging and fewer re-publishes. Share pilot wins within weeks and expand when the numbers support it.