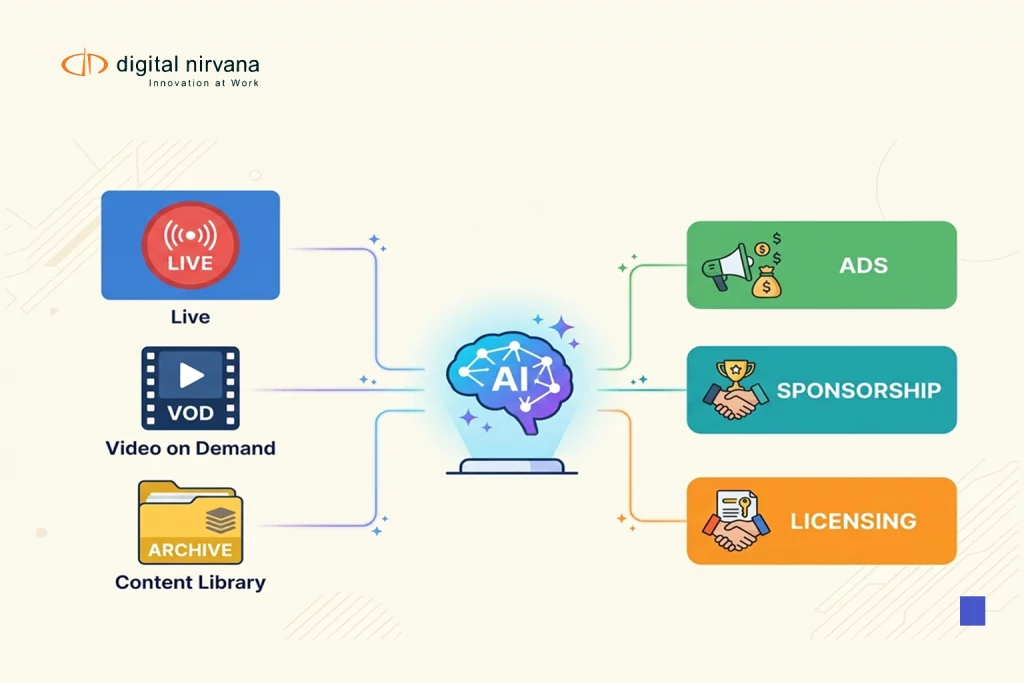
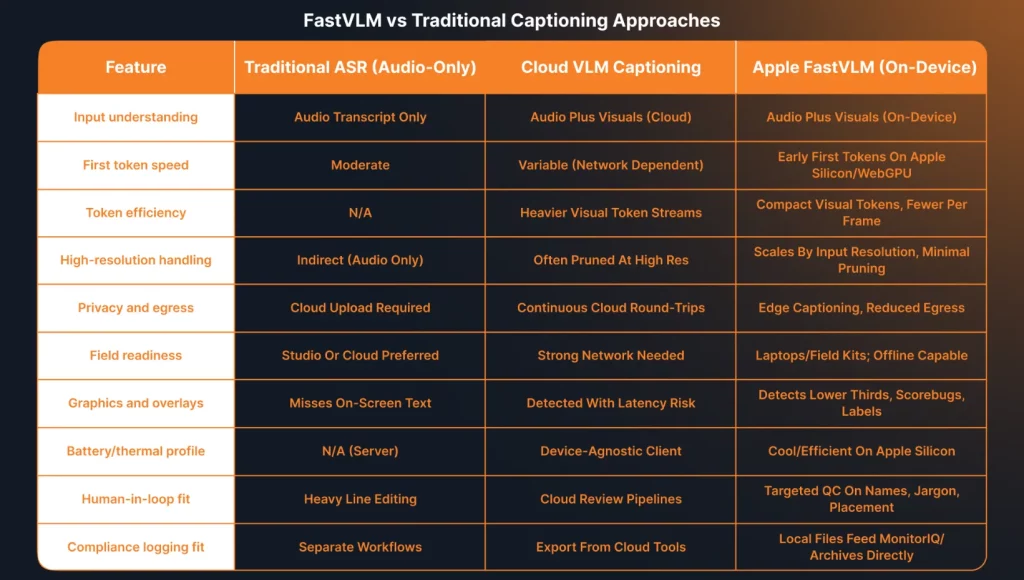
Apple’s FastVLM video-captioning runs on-device, outputs first tokens fast, and handles high-resolution video frames without heavy token pruning. The model ships in compact sizes that work on Apple Silicon and in the browser through WebGPU, which puts real-time captioning within reach for field crews and editors on laptops. A hybrid vision encoder emits fewer visual tokens, which cuts latency while preserving detail for scenes with motion and overlays. Teams can expect faster drafts, better context, and lower egress costs when they keep caption generation closer to the camera. The shift pairs well with a human-in-the-loop review for legal defensibility and brand control.
How Digital Nirvana accelerates captioning pilots in practice
Our services at Digital Nirvana help teams turn Apple AI captioning ideas into day-one wins. Editors can draft, edit, and export captions in TranceIQ, while control rooms record airchecks and attach sidecar files in MonitorIQ. Content ops enrich files with searchable tags in MetadataIQ and switch to live events with Live Captioning when shows go on air. We map a lean workflow from camera ingest to archive so pilots hit latency targets and legal review without heavy retraining. If you run mixed vendors or older devices, we still slot in through watch folders and simple API calls.
FastVLM’s core strengths show up when teams chase seconds. Real-time and near-real-time environments need low-latency paths from camera to caption to screen. The model’s compact visual tokens and responsive language decoding support those paths while keeping quality high. Edge execution protects sensitive content and helps crews work in bandwidth-constrained venues. Apple’s Camera App and third-party capture tools can hand frames to a local FastVLM service. Wearables like Apple Watch can show glanceable QC alerts and start or stop caption capture. That flow keeps operators in the Apple ecosystem and reduces friction on set.
Frame-by-frame understanding with a visual language model
A visual language model links pixels to words. FastVLM’s encoder turns each frame into a short sequence of tokens that capture objects, text on screen, and layout. The language model then uses those tokens to write captions that follow action and context. As a scene shifts, the next frame produces a new token set, so the captions adapt quickly. That frame-aware loop helps with sports, live interviews, and mixed graphics.
For a deeper look at control-room monitoring practices that support this flow, see our digital broadcast monitoring system guide.
Edge captioning for privacy without constant cloud calls
Many productions handle sensitive footage, unreleased ads, and embargoed promos. Edge captioning keeps that content on the device, which limits exposure. The team can store drafts locally or inside a secure media network, then sync a reviewed file into the archive. With fewer cloud calls, organizations also avoid surprise egress fees.

Inside the model: how FastVLM processes visuals and language
FastVLM’s design pivots on a hybrid vision encoder that stays efficient at high resolution. The encoder emits fewer tokens but preserves detail, which helps the language model describe small objects, lower-thirds, and scoreboard text. Because the model scales by input resolution rather than extra pruning, teams can tune speed and quality by choosing capture size and frame sampling.
Hybrid vision encoder that emits fewer visual tokens
The encoder mixes convolutional and transformer-style operations to capture structure and semantics. It compacts visual information into a small token set that still carries the fine detail captions need. Fewer tokens shorten the path between frame arrival and caption output. That shortening becomes the difference between on-time and late subtitles in a live control room.
Scaling high-resolution inputs without heavy token pruning
Instead of piling on token pruning tricks, FastVLM scales by adjusting input resolution. That keeps the pipeline simple and predictable. Teams can pick a resolution that balances clarity and compute for each show. Sports producers might keep a higher resolution during fast action, while talk shows can step down to save power and heat. The model’s steady behavior across settings makes it easier to operate under pressure.
What the design means for speed, battery life, and hardware
A compact token stream reduces compute on both the vision and language sides. Laptops and desktops run cooler, which stretches battery life in field use. Control rooms can reserve their GPUs for rendering, graphics, and switching while CPUs and NPUs handle captioning. Hardware choice broadens because the model’s smallest variants still maintain useful accuracy.
B-parameters in practice for FastVLM sizes
Expect small B-parameter class variants in the single-digit billions for field use and larger options for workstations. Use the smaller models for on-device tests and reserve mid-B models for control rooms that want extra accuracy. Tie your choice to latency and battery goals first, then tune precision with in-domain lexicons.
Editorial and engineering wins from faster automated captioning
When captioning keeps pace with the shot, teams create better content and avoid rework. Producers get a cleaner program feed, editors finish faster, and compliance teams capture complete logs without gaps. The payoff shows up in live coverage as well as VOD, highlights, and social cuts.
Live news, sports, and events with tighter caption timing
Fast VOs, sideline interviews, and moving shots put pressure on caption timing. With earlier first tokens, captions appear on screen closer to the spoken words or visible action. Audiences see fewer late lines and fewer overlaps. Control rooms spend less time back-timing captions after the fact. That improvement compounds across a show and reduces fatigue for operators.
Teams can build a house checklist from our accurate captioning guide. FastVLM’s token design preserves layout cues and on-screen text, so the language model can include names, places, and labels correctly. Editors still review and fix brand terms and speaker names, but they start with strong drafts. The net effect is fewer fixes per minute of media and better search downstream in the archive.
Producers who manage multichannel listening can also scan our notes on media listening tools for broadcasters. Automatic captions that start quickly and track scene changes save minutes on every clip. Producers can publish with confidence, then circle back to refine captions on high-traffic pieces. Faster turnaround also supports A/B testing for titles, thumbnails, and micro-copy because the caption track lands sooner.
U.S. accessibility and compliance considerations to keep in view
Automated captioning must meet legal expectations and audience needs. In the United States, broadcasters and OTT platforms follow FCC rules that cover accuracy, timing, completeness, and placement. The ADA and CVAA extend those expectations to apps, devices, and internet video. Teams that run pilots with FastVLM should align model output, human QC, and logging so captions meet both the letter and spirit of the rules.
$1$2, and the FCC details those standards in its Closed Captioning on Television consumer guide. FastVLM can help with timing and completeness by producing early first tokens and keeping up with the program feed. Human editors should still validate accuracy and fix names, jargon, and homophones. Proper placement avoids covering graphics, tickers, and sponsor bugs.
$1$2. For web and app experiences, the Department of Justice explains caption expectations in its ADA web guidance on effective communication. That means captions must work on phones, TVs, set-top boxes, and apps. Teams should test FastVLM-generated files across devices, players, and distribution partners. Consistent styling, safe regions, and format support keep captions readable everywhere. Logs should document that each airing included compliant captions.
$1$2. For terminology clarity across tracks, review our primer on subtitles vs. closed captioning. SDH tracks add speaker tags and sound effects, which improve access for deaf and hard-of-hearing audiences. Descriptive text supports viewers with low vision by summarizing key visuals. FastVLM can draft these variants quickly, then editors can apply house style and legal terminology. That approach keeps quality high without long delays.
Cost shifts when captioning moves closer to the camera
Edge captioning changes the cost stack. Teams spend less on GPU hours in the cloud and reduce egress by keeping frames local. Hardware and staffing shift toward field kits and QC lanes. The model’s efficiency allows smaller devices to handle more minutes per charge, which lowers total cost of ownership over a season.
Less spend on GPU hours and egress with edge inference
Every cloud hop costs money and time. Running FastVLM on laptops or workstations keeps raw video local and sends only caption files to storage. That switch reduces egress fees and compresses timelines. Teams can reserve cloud GPU budgets for heavy transcoding and AI enrichment that truly require it.
On-device processing that fits MAM and PAM touchpoints
Captioned files must flow into media asset managers, production asset managers, and compliance archives. On-device processing can still feed those systems through watch folders, APIs, or plug-ins. Operators drop a reviewed caption file and the MAM ingests it with the right metadata. That fit keeps old habits intact while improving speed.
Human-in-the-loop QC only where it truly adds value
Use human review where it moves the needle. Proper nouns, domain jargon, and sponsor names deserve careful checks. Silence detection and shot boundaries can gate where editors focus. With stronger drafts from FastVLM, QC time shifts from line edits to targeted corrections and format checks.
Ecosystem signals developers care about
FastVLM grows faster when the ecosystem rallies around it. You can see traction in download counts, sample code, and field notes that move from demo to daily use. Hugging Face collections host weights and spaces that make a quick download and try cycle painless. GitHub fills with wrappers, MLX examples, and WebGPU starters that wire cameras, buffers, and caption sinks. Reddit threads surface real-world bugs and workarounds, which turn into fixes in the next updates from maintainers and partners.
Community momentum you can measure
Watch three metrics each week. Track Hugging Face downloads and space usage. Track GitHub stars and issues on MLX and FastVLM-adjacent repos. Track Reddit post volume and upvotes on on-device Artificial Intelligence captioning topics. Rising lines across all three point to adoption beyond press releases.
Sample code, weights, and responsible releases
Developers want fast starts and clear licenses. Link pilots to a vetted Hugging Face model card, pin a specific commit in GitHub, and cache a local download so shows do not stall. Document your changes in a fork and submit improvements upstream when they help the community.
Update cadence and where to watch
Stay close to Apple’s Machine Learning Research blog for release notes and model updates. Follow MLX on GitHub for new operators and accelerated kernels. Scan Reddit for field reports from live events and breaking newsrooms. Share notable updates with editors and engineering so your team benefits the same day, not next quarter.
Developer notes that matter for pilots and proofs of concept
Engineers need a clear plan before going live. FastVLM offers models that run on Apple Silicon and in modern browsers with WebGPU. Your pilot should define latency budgets, accuracy goals, and security rules before the first show. Domain-specific datasets help the model handle names, place labels, and sponsor terms with higher confidence.
Apple MLX support and WebGPU considerations
Apple’s MLX framework streamlines local inference on Apple Silicon. WebGPU enables real-time captioning in compatible browsers for quick demos and field tests. Engineers should verify device support, camera permissions, and thermal behavior during long sessions. Build a fallback path for older machines that lack WebGPU or enough memory.
Latency targets, accuracy metrics, and domain datasets
Pick targets you can measure. Track time to first token, time to full caption line, and median end-to-end latency. Measure word error rate and entity accuracy for people, teams, and locations. Feed the model in-domain names and lexicons so it learns house style. Review results per show type and keep a changelog.
Security, audit logging, and retention requirements
Treat captions as records. Store files with checksums and timecodes. Keep audit logs that show who edited what and when. Map retention rules to your legal and contractual obligations. For sensitive shoots, run capture and caption on a secure subnet and avoid external uploads.
Ground-truth sets and real-world clip selection
Build a ground-truth set from your own shows. Include clean audio, crowd noise, music beds, and fast cuts. Label speaker turns and jargon. This set becomes your north star for tuning and vendor comparisons. Refresh it each quarter as story formats evolve.
A/B testing protocols for WER and timing drift
Run A/B tests with clear controls. Compare FastVLM variants and settings against your baseline. Track word error rate, timing drift in frames, and placement issues. Use blind reviews by editors to score readability and brand fit. Publish a short memo after each test so stakeholders see progress.
Buyer’s checklist for Apple AI captioning rollouts
A good rollout aligns use cases, devices, budgets, and people. Start with a compact pilot, then scale by show type once you meet targets. Keep stakeholders in the loop with simple status reviews and clips that show real gains.
Use cases, success criteria, and stakeholder alignment
Write a one-page brief per use case. Define success criteria like caption latency, accuracy on names, and show readiness. Identify owners in engineering, editorial, and legal. Share a weekly note on wins, misses, and next steps.
Device capabilities, browsers, and network constraints
Inventory your Macs and browsers. Confirm which machines support WebGPU and which run MLX well. Note camera types, capture cards, and audio paths. Test on congested networks and mobile hotspots to see how the system holds up. Prioritize Pro MacBook configurations with ample unified memory for smooth WebGPU demos and MLX runs. Pair field kits with wearables for operator alerts and a simple foot pedal or hotkey to confirm line breaks.
Budget, staffing, and change-management planning
Budget for pilot hardware, editor time, and training. Assign a vendor point of contact and a show captain who owns the rollout. Create a simple playbook for operators with screenshots and checklists. Plan a short retro after the first three shows to lock improvements.
Pilot scopes, milestones, and executive readouts
Set a 4 to 6 week pilot with milestones. Week 1 covers setup and a dry run. Weeks 2 and 3 exercise live and near-live shows. Week 4 reviews metrics and decisions. Share a concise readout with clips and a go or no-go call.
Risk mitigation and fallback caption pipelines
Keep a fallback path ready. Maintain your current caption vendor or cloud ASR for backup. Store a tested template that switches feeds or toggles caption sources. Run a failover drill before the first live event so operators act without hesitation.
Field kits with Pro MacBook, wearables, and Camera App handoffs
Build a simple kit list. Use a Pro MacBook with Apple Silicon, an external mic, and a capture dongle. Add an Apple Watch for operator alerts and quick pause or resume. Route frames from the Camera App or your switcher into the local service and write caption files to a watched folder. Document the steps with screenshots and a one-page checklist.
What to watch next from Apple’s FastVLM roadmap signals
Model families evolve. Watch Apple’s public releases for larger or more efficient variants and tighter browser support. Expect better multimodal search that ties captions, transcripts, and on-screen text to smarter media metadata. Look for tools that let editors correct captions in real time and feed those fixes back into confidence scoring. Keep an eye on adoption metrics across news, sports, and creators over the next 6 to 12 months.
. If you want practical examples of this, read our walkthrough on AI metadata tagging for media searchability. Editors can locate shots by visual and textual cues in one query. Efficient encoders make per-frame tags feasible, which boosts discovery and rights checks. Expect tighter links between captions and metadata inside PAM and MAM systems.
Real-time caption editing and adaptive confidence scoring
Live tools will move beyond simple insertion and deletion. Editors will see confidence scores per token and nudge lines that fall below thresholds. Systems will learn from fixes and adjust language choices on the fly. That loop reduces future edits and raises trust.
Industry-wide adoption indicators over the next 6 to 12 months
Watch for three signals. First, more broadcasters will demo browser-based captioning during events. Second, OTT platforms will report shorter turnaround for VOD captions. Third, vendors will ship plug-ins that bind FastVLM outputs into compliance and archive tools. Those signals point to lasting change, not a one-off demo.
At Digital Nirvana, we help you scale captioning without retooling
At Digital Nirvana, we help you hit caption quality goals without ripping out your stack. TranceIQ streamlines editing and delivery for multiple caption formats, while MonitorIQ preserves audit-ready airchecks and caption timelines. MetadataIQ writes rich, searchable tags that make every captioned clip easier to find and reuse. Our live captioning team covers events that need human oversight from the first whistle to the sign-off. When you need a plan you can run next week, we set milestones, train staff, and measure results with simple scorecards.
A faster visual language model shifts captioning from a slow back-office step to a front-line assist. Teams win when captions start sooner, carry more context, and land in the archive with clean logs. The path to production looks manageable with Apple-compatible hardware and Digital Nirvana products that bridge gaps.
- Key benefits in one look:
- On-device speed delivers earlier first tokens and smoother live captions.
- Compact visual tokens preserve context and reduce compute.
- Edge execution lowers egress and protects sensitive footage.
- Human review targets names, jargon, and style instead of basic fixes.
- Clean audit trails and metadata lift compliance and search.
- On-device speed delivers earlier first tokens and smoother live captions.
- Practical steps to move forward:
- Define latency and accuracy targets per show type.
- Build a small in-domain ground-truth set and update it quarterly.
- Pilot with MLX or WebGPU on Apple Silicon and capture metrics.
- Feed reviewed captions into MonitorIQ and MetadataIQ for logging and search.
- Share wins with short clips and plan the next wave of shows.
- Define latency and accuracy targets per show type.
- Closing thought:
- Speed only matters when it shows up on screen. Pair FastVLM’s gains with disciplined QC and the right handoffs, and your captions will prove it every day.
- Speed only matters when it shows up on screen. Pair FastVLM’s gains with disciplined QC and the right handoffs, and your captions will prove it every day.
FAQs
Is FastVLM usable for live broadcast captions today?
Yes, in pilot form. Teams run FastVLM on Apple Silicon or in WebGPU for demos and controlled live segments. You should set strict latency and accuracy targets, then keep your current caption path as a fallback during the trial. Many shows will see value first in near-live highlights and breaking cut-ins. Scale once editors hit quality marks consistently.
How is Apple AI captioning different from traditional ASR?
Traditional ASR listens to audio and prints words. Apple’s FastVLM sees the frame and reads scene context along with text on screen. That visual context helps with names, graphics, and action descriptions. You still need an audio transcript, but the visual tokens let the model write captions that match what viewers see. The blend produces stronger lines with fewer edits.
Does FastVLM work offline for sensitive content?
Yes, that is one of the main draws. Running on-device means crews can caption in the field without sending raw footage to the cloud. Stores with strict compliance needs can keep all files on a secure network. You can sync only the reviewed caption files to shared storage or the MAM when policy allows.
What accuracy and latency should teams expect initially?
Targets depend on show type, device, and model size. For live shows, aim to keep latency to a small number of frames from speech or action to on-screen text. For accuracy, measure word error rate and named entity correctness on your own ground-truth set. Expect steady improvement as you tune lexicons, fix style, and upgrade devices.
How can Digital Nirvana help operationalize a pilot?
We connect FastVLM outputs to TranceIQ for guided editing and to MonitorIQ for compliance logging. MetadataIQ enriches caption files for search and reuse. Our team helps define metrics, build test sets, and train editors on efficient review. We support phased rollouts across news, sports, and OTT so you see value fast.