Metadata automation can make a media library feel instantly smarter, until one wrong tag sends a producer to the wrong clip, a brand gets flagged incorrectly, or search results stop feeling reliable.
That is why governance matters. When you treat AI-generated metadata like a controlled system, with thresholds, review queues, and audit trails, you get speed without sacrificing trust. This is especially important in news and sports, where content moves fast and small errors spread quickly.
This guide shows a practical governance model for metadata automation, including confidence thresholds, human-in-the-loop metadata review, and audit trails that make every decision explainable.
Why Metadata Automation Needs Governance
Automation is not the risky part. Ungoverned automation is.
In most media operations, metadata changes have consequences:
- Search and reuse decisions happen based on tags and transcripts.
- Compliance and rights checks rely on what the system says is inside the content.
- Editors trust the first few results, and rarely have time to validate everything.
That is why AI governance is typically described as a set of guardrails and processes that keep AI systems safe, accountable, and controllable. IBM frames AI governance in exactly that way.
A governance-first approach does three things:
- Reduces false positives that erode trust.
- Prevents low-confidence outputs from quietly polluting your library.
- Creates a record of what changed, who approved it, and why.
Confidence Thresholds That Match Real Workflow Risk
Confidence scores are useful only if you turn them into consistent decisions. Thresholding is the simplest way to do that, because it defines when the system auto-applies metadata and when it asks a human.
Use Different Thresholds For Different Metadata Types
A single global threshold is where teams get stuck. Faces, logos, and speech-to-text do not carry the same operational risk.
Digital Nirvana recommends setting thresholds by task, for example, allowing high-confidence face tags for discovery, while routing logo detections to review because the risk is higher.
A practical way to implement this is to group metadata into risk tiers.
Low Risk Examples
- Broad topics, non-sensitive objects, and general categories used for discovery
Medium Risk Examples
- People’s names in non-sensitive contexts, teams, locations, and show names
High Risk Examples
- Sponsor logos, regulated terms, rights-sensitive labels, compliance triggers, anything that can create business risk
A Simple Threshold Routing Model
| Confidence Band | Action | Best For |
| High Confidence | Auto-apply, log it, sample-audit later | Low-risk discovery tags |
| Medium Confidence | Route to the quick review queue with one-click approve or reject | Most entity tags and key topics |
| Low Confidence | Route to deep review or hold back from the library | Risky tags and unclear detections |
This structure protects speed. It also keeps the review queue focused on the decisions that actually matter.
Tie Thresholds To Precision And Recall, Not Opinions
Threshold tuning is where many teams get political. Keep it measurable.
Precision and recall are the right language here because they directly capture false positives and misses.
A practical tuning approach:
- Start conservatively with high-risk metadata and prioritize precision.
- Start balanced for medium-risk metadata, tune based on review workload.
- For low-risk discovery tags, allow more recall, then use sampling to prevent drift.
Human Review Queues That Do Not Slow Teams Down
Human review works when it feels like a normal part of the workflow, not a separate job.
A queue should exist for one reason: to concentrate human attention where it buys the most trust.
Design Review Queues Around Triage
Instead of one massive queue, use three lanes.
Lane 1: Quick Review
- Medium confidence tags
- One-click approve or reject
- Short SLA, handled by producers, loggers, or librarians
Lane 2: Specialist Review
- High-risk categories like sponsorship logos, sensitive entities, and compliance terms
- Requires context, policies, and sometimes a second reviewer
Lane 3: Exception Handling
- Anything the system cannot classify cleanly
- Broken references, low-quality audio, and ambiguous identity
This approach mirrors how real-time tagging systems are often implemented in live workflows, where automated metadata is generated quickly, then review and improvement loops are built into operations.
Keep Queues Small With Two Controls
Control 1: Scope
Do not queue everything. Queue only what is medium confidence, high impact, or policy relevant.
Control 2: Sampling
Sample a small percentage of auto-approved outputs. Sampling catches silent failures and helps you tune thresholds without flooding teams.

Audit Trails That Make Metadata Defensible
Audit trails are what turn “the system said so” into “we can prove what happened.”
A widely used definition describes an audit trail as metadata that records actions related to the creation, modification, or deletion of records, without overwriting the original history. The World Health Organization uses this language in a data integrity guideline.
For media teams, audit trails support:
- Internal investigations when search results look wrong.
- Quality coaching, because you can see patterns by tag type or reviewer.
- Compliance defensibility, because you can show who approved a decision and when.
Digital Nirvana’s newsroom automation guidance also emphasizes audit trails, including logging who changed what field and when, so issues can be investigated quickly and fairly.
What To Log In A Metadata Automation Audit Trail
| Audit Field | Why It Matters |
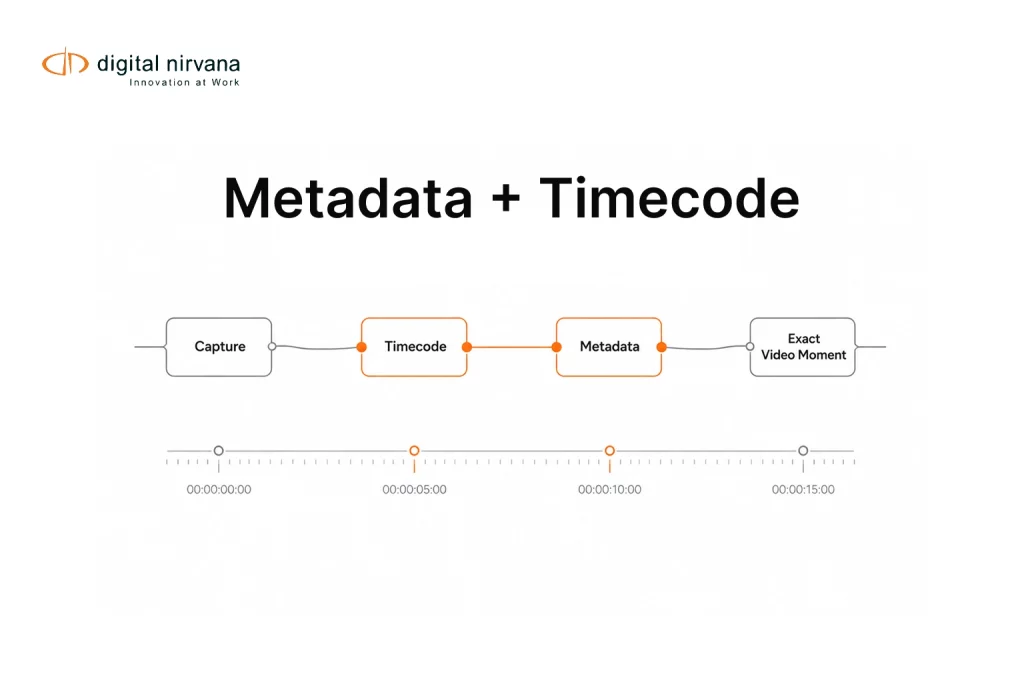
| Asset ID and Time Range | Connects metadata to the exact content moment |
| Metadata Type and Value | Shows what was proposed and applied |
| Confidence Score | Explains why it was auto-applied or routed |
| Model Version and Ruleset Version | Enables reproducibility, supports postmortems |
| Action Taken | Auto-applied, held, sent to review, rejected |
| Reviewer Identity | Accountability and training insights |
| Timestamp | When the decision happened |
| Before and After Values | Shows what changed, not just the final state |
| Reason Code | Speed analysis, such as “alias mismatch” or “logo ambiguity”. |
How Long To Keep Logs
Keep logs long enough to match your operational reality:
- Content disputes and rights questions can surface months later.
- Search drift gradually appears, and you need history to diagnose it.
You do not need a single perfect retention rule for every team, but you do need a written policy that aligns with your risk profile.
Operating Rhythm: Sampling, Drift, And Continuous Improvement
Governance is not a one-time setup. It is a rhythm.
Weekly
- Review queue volume, clear backlog.
- Track top false positive categories.
- Flag policy changes that need taxonomy updates.
Monthly
- Adjust thresholds per tag type.
- Retrain alias lists and entity dictionaries.
- Review sampling results from auto-applied metadata.
Quarterly
- Run a structured evaluation against a gold set.
- Review audit trail findings for recurring issues.
- Update governance policies and access controls.
This aligns well with broader AI risk guidance that encourages oversight, tracking, documentation, and continuous monitoring. The National Institute of Standards and Technology highlights the need for human oversight roles, policies, and documented processes in its AI risk management materials.
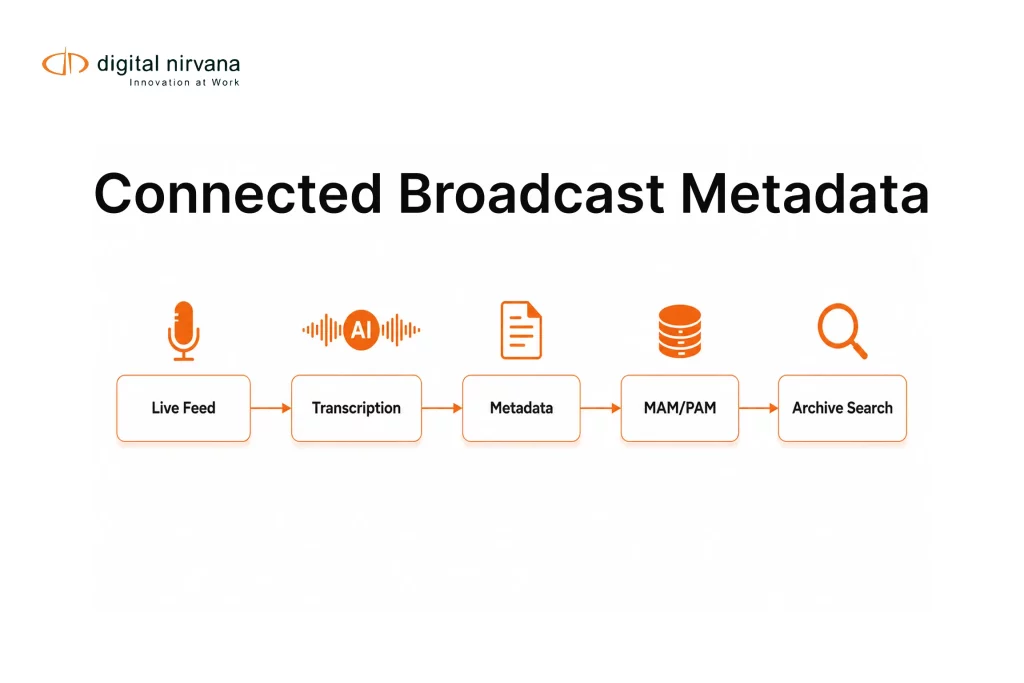
Where MetadataIQ Fits In A Governed Workflow
If your goal is metadata automation that improves search inside existing PAM and MAM environments, governance must live where teams work.
MetadataIQ is positioned as an indexing and integration layer that writes time-coded metadata back into PAM, MAM, and newsroom systems, rather than forcing teams into a separate repository.
FAQs
Metadata automation uses AI to generate descriptive and time-based metadata, such as transcripts, people, topics, teams, and on-screen text, so content becomes searchable faster and at scale.
Confidence thresholds define when AI outputs are auto-applied versus routed to human review. They help control the precision-recall trade-off and prevent low-confidence guesses from polluting your library.
Set thresholds by metadata type and business risk, then tune them using precision, recall, and queue volume. Start conservative for high-risk tags, and use sampling to refine over time.
Items with medium confidence, high impact, or policy sensitivity should go to review. The goal is not to review everything; it is to review what protects trust and reduces risk.
An audit trail is metadata about metadata; it records who changed what, when, and how, so decisions can be reconstructed later.
Conclusion
Metadata automation delivers the most value when teams can trust it. Confidence thresholds keep decisions consistent, review queues keep humans focused on the right edge cases, and audit trails make every change explainable. Together, they stop false positives from spreading, protect sensitive workflows, and keep search reliable as your library grows.
Key Takeaways:
- Set confidence thresholds by metadata type and risk level, not as one global number.
- Route medium confidence outputs to fast review queues, and reserve deep review for high-risk categories.
- Use sampling audits to catch silent failures and keep queues manageable.
- Maintain audit trails that record what changed, who approved it, and which model and rules were used.
- If you want governance to work in production, choose a workflow that writes governed metadata back into the PAM and MAM tools teams already use.